728x90
전체 글
- [웹크롤링] web_crawling 2024.05.28 1
- [머신러닝] Spring 과 연동하여 서비스 구현 2024.05.28
- [머신러닝] 군집 ( 고객분류 ) 2024.05.28
- [머신러닝] 변수 선택법 ( feature selection ) 2024.05.28
- [머신러닝] 회귀 및 평가지표 2024.05.27
- [머신러닝] 과적합 및 하이퍼파라미터 2024.05.27
- [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 2024.05.24
- [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) 2024.05.24
[웹크롤링] web_crawling
2024. 5. 28. 16:09
[머신러닝] Spring 과 연동하여 서비스 구현
2024. 5. 28. 16:06
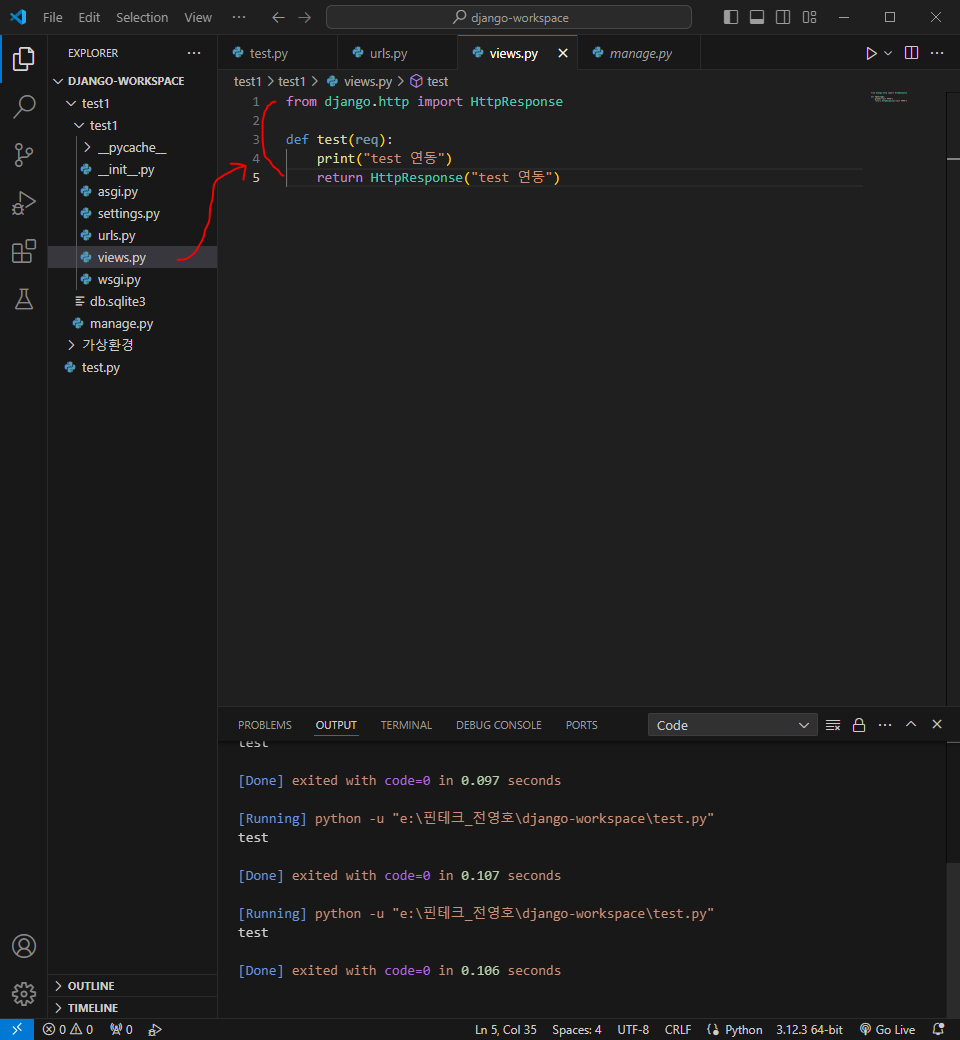
Spring 과 연동하여 서비스 구현
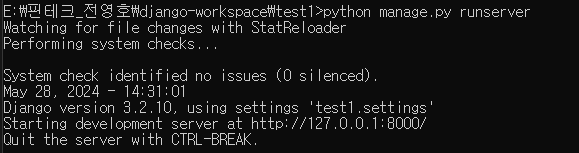
Welcome to Python.org
The official home of the Python Programming Language
www.python.org
파이썬 설치

vscode 로 workspace 접속
google 에 사이킷런 모델 저장 검색
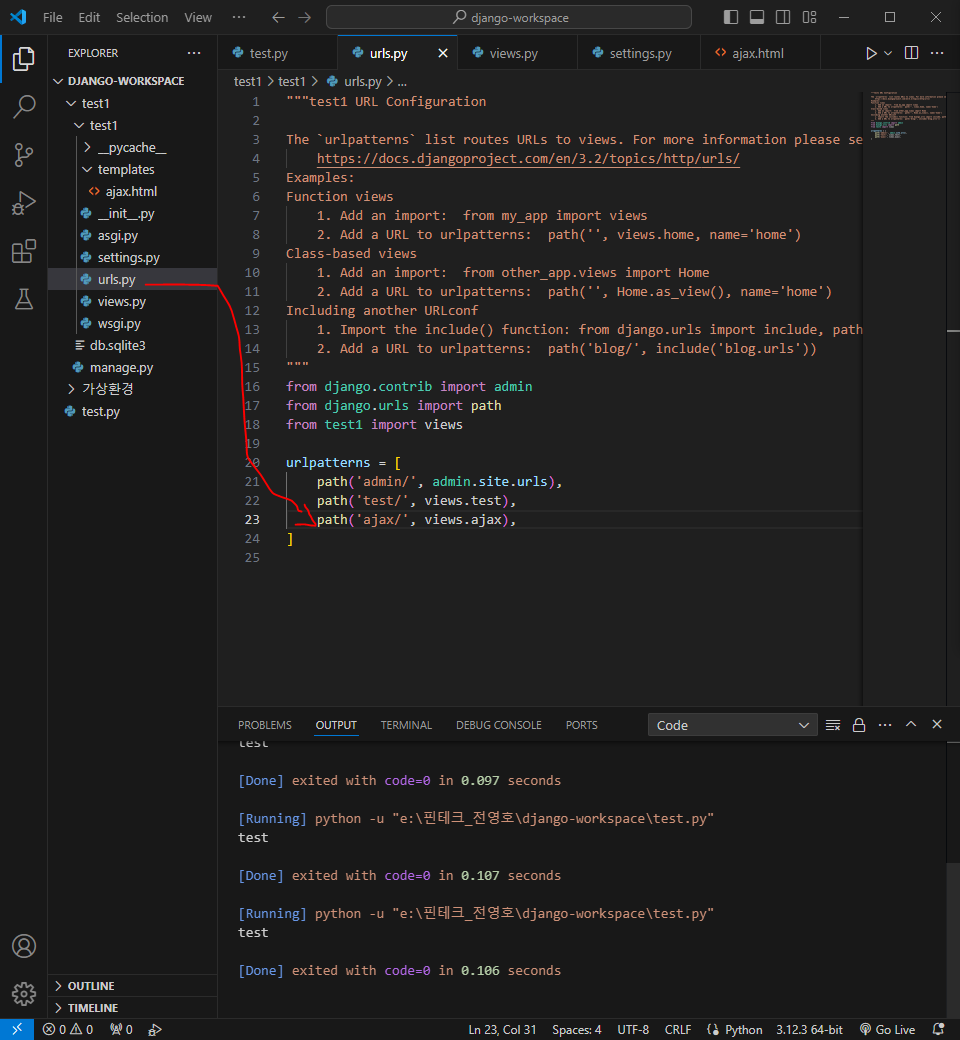
▲ 모델을 생성한 뒤 서버를 종료시켰다 다시 실행시키면 모델을 다시 학습시켜야 하기 때문에 모델을 파일로 저장해둔 뒤 사용 ▲

▲ 위 설정은 local 환경에 설치 ▲
가상환경으로 설치하여 관리하는 방법



가상환경 내에서 pip install 을 사용해 가상환경 별로 각각 다른 버전의 라이브러리를 설치하여 관리할 수 있다

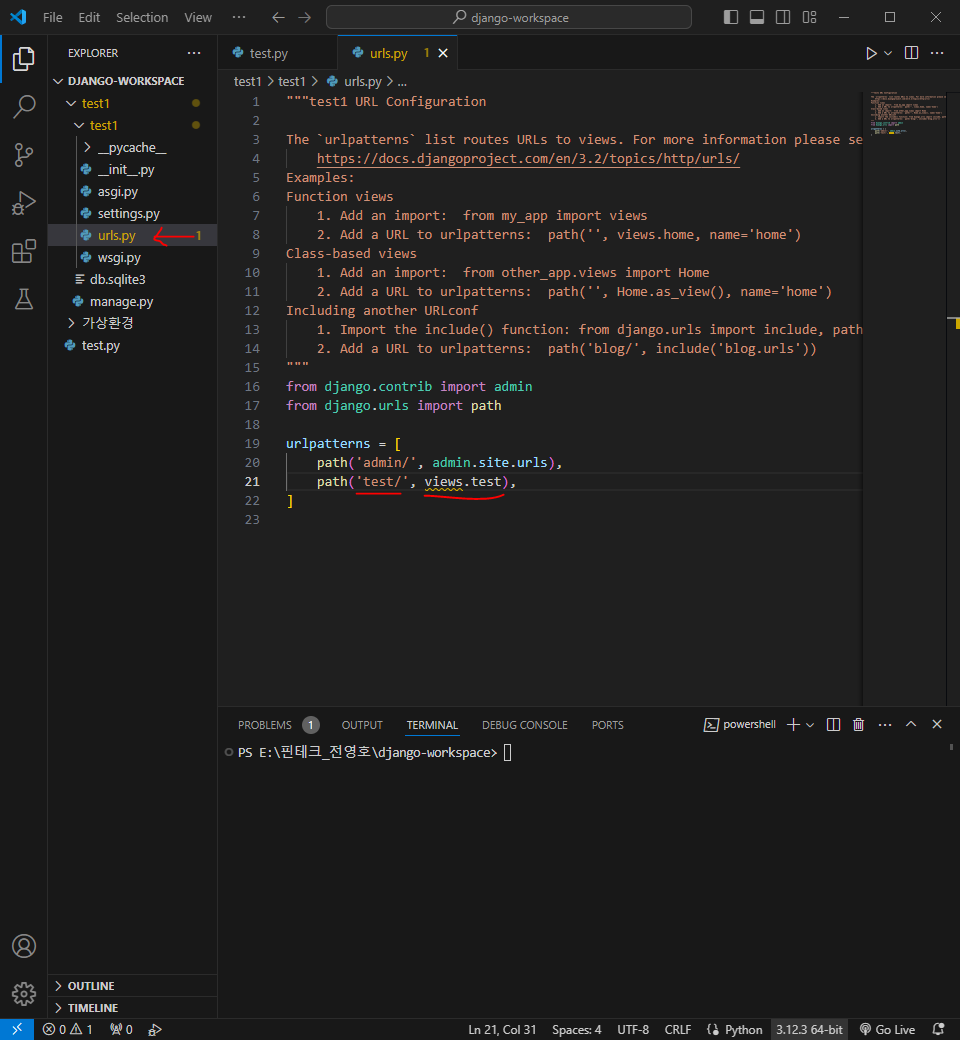

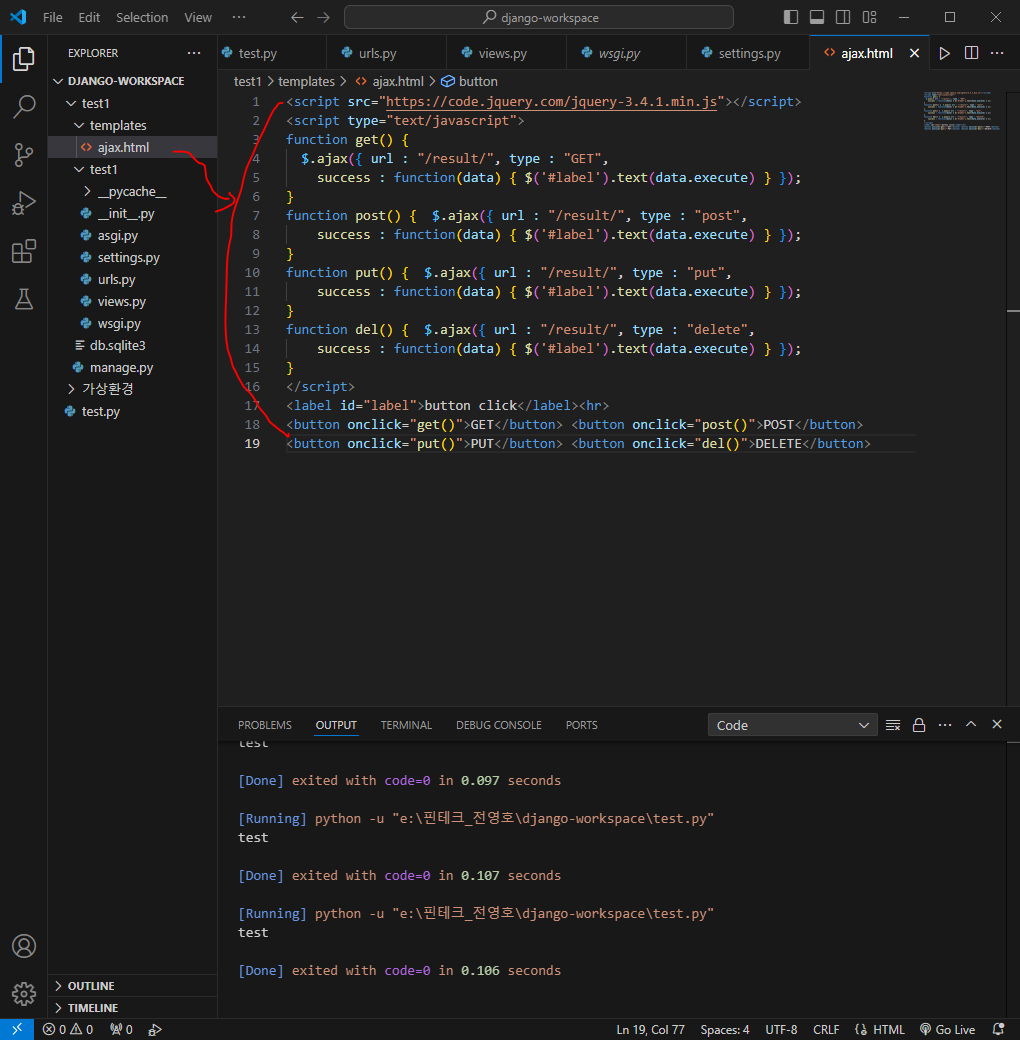
<script src="https://code.jquery.com/jquery-3.4.1.min.js"></script>
<script type="text/javascript">
function get() {
$.ajax({ url : "/result/", type : "GET",
success : function(data) { $('#label').text(data.execute) } });
}
function post() { $.ajax({ url : "/result/", type : "post",
success : function(data) { $('#label').text(data.execute) } });
}
function put() { $.ajax({ url : "/result/", type : "put",
success : function(data) { $('#label').text(data.execute) } });
}
function del() { $.ajax({ url : "/result/", type : "delete",
success : function(data) { $('#label').text(data.execute) } });
}
</script>
<label id="label">button click</label><hr>
<button onclick="get()">GET</button> <button onclick="post()">POST</button>
<button onclick="put()">PUT</button> <button onclick="del()">DELETE</button>
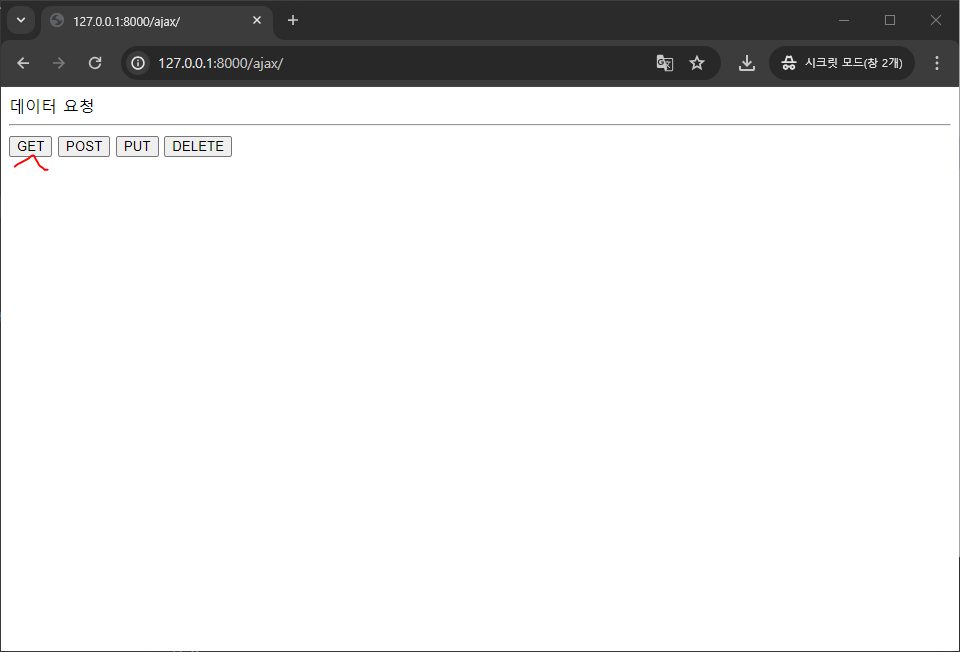
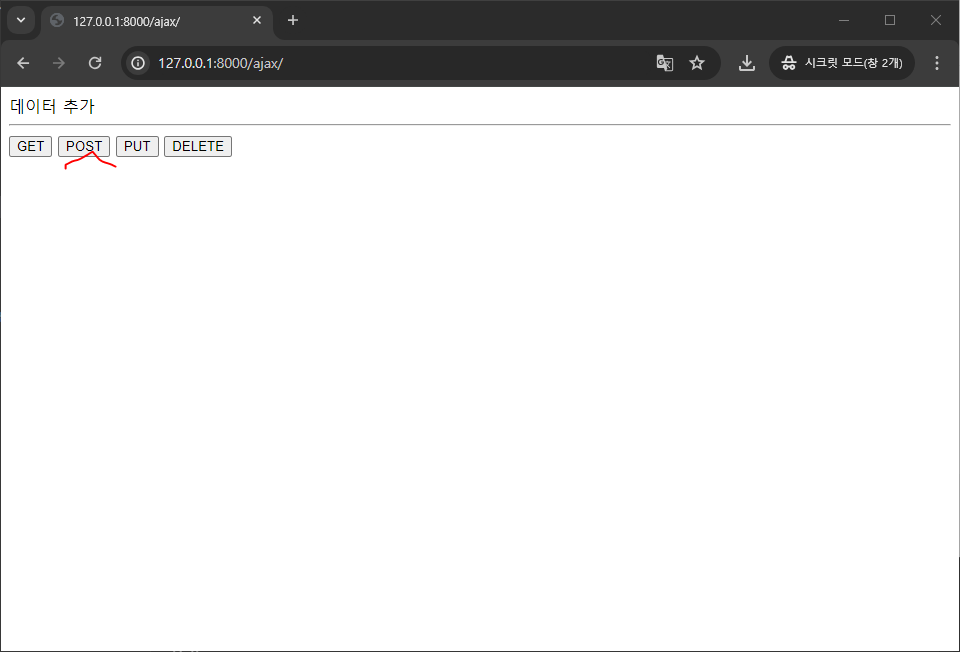
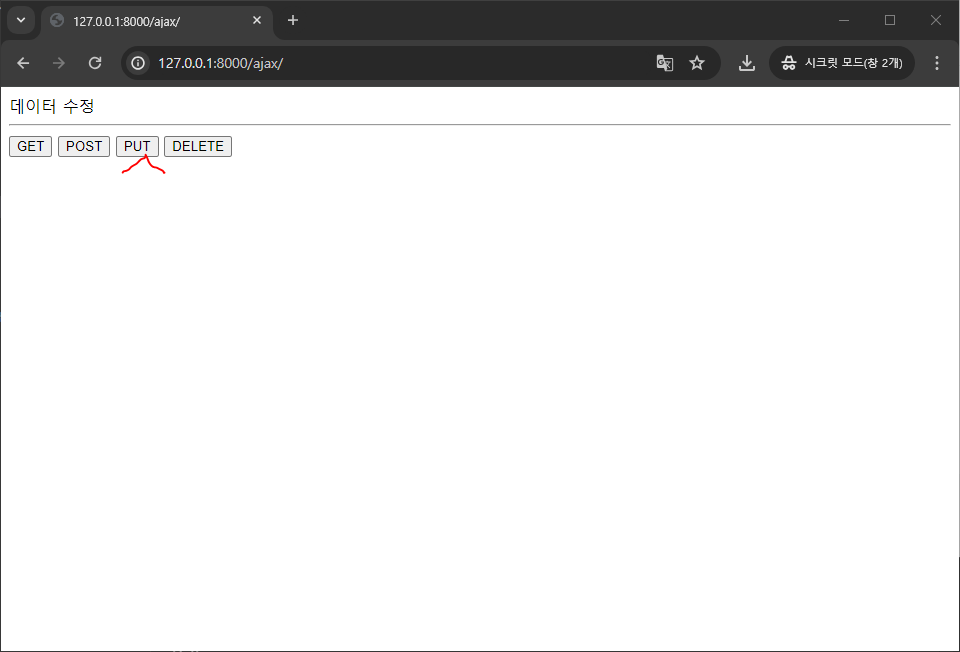
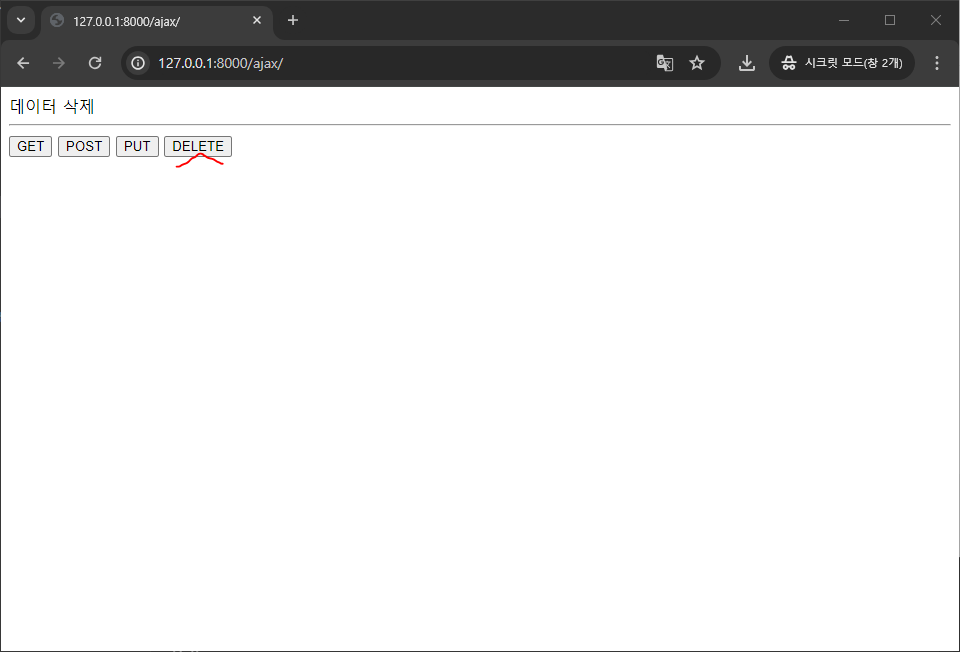
접속하면 에러가 뜨는데 이유는 서로 다른 서버에 데이터를 요청하게되면 에러가 발생함...!!!
이 에러를 해결해주기 위해선 라이브러리 설치가 필요하다

CORS(Cross-Origin Resource Sharing) : 서로 다른 서버들 끼리 데이터를 주고 받으려 할때 발생하는 오류
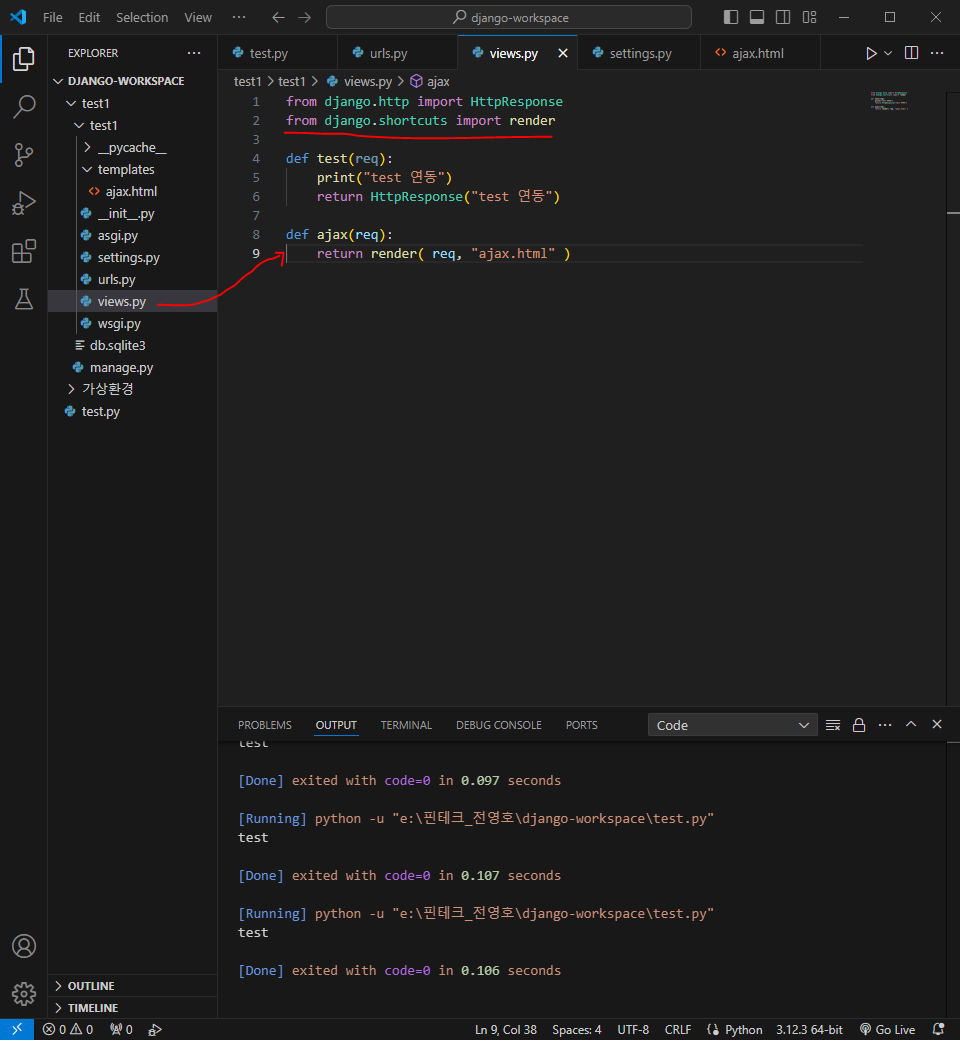
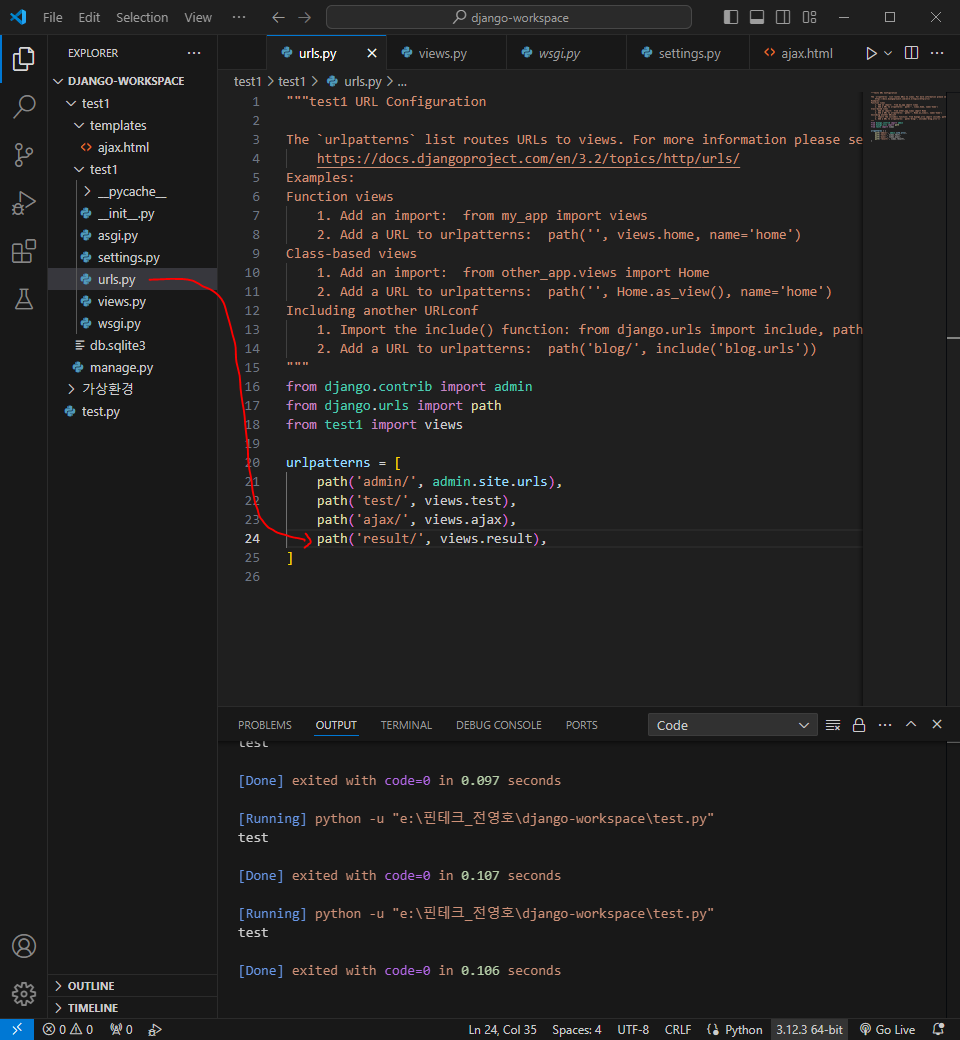
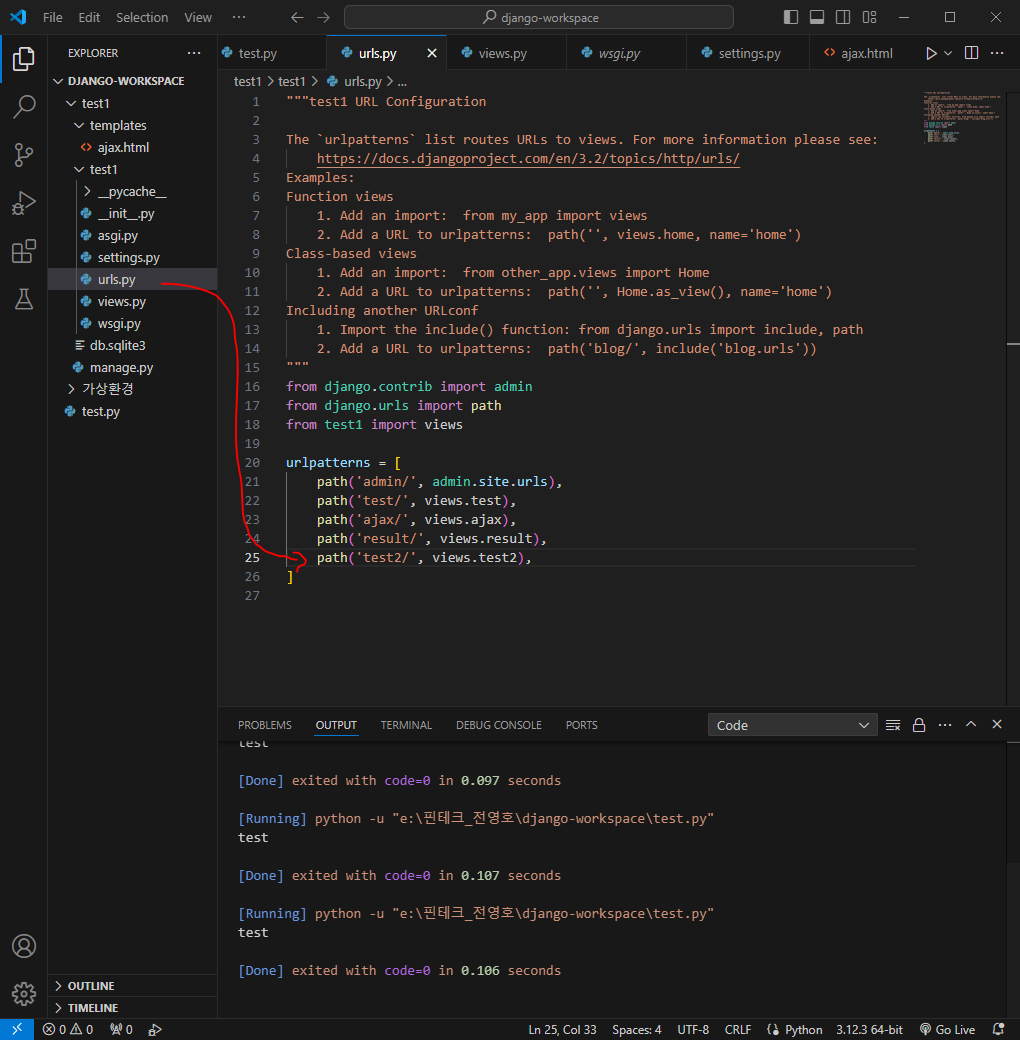
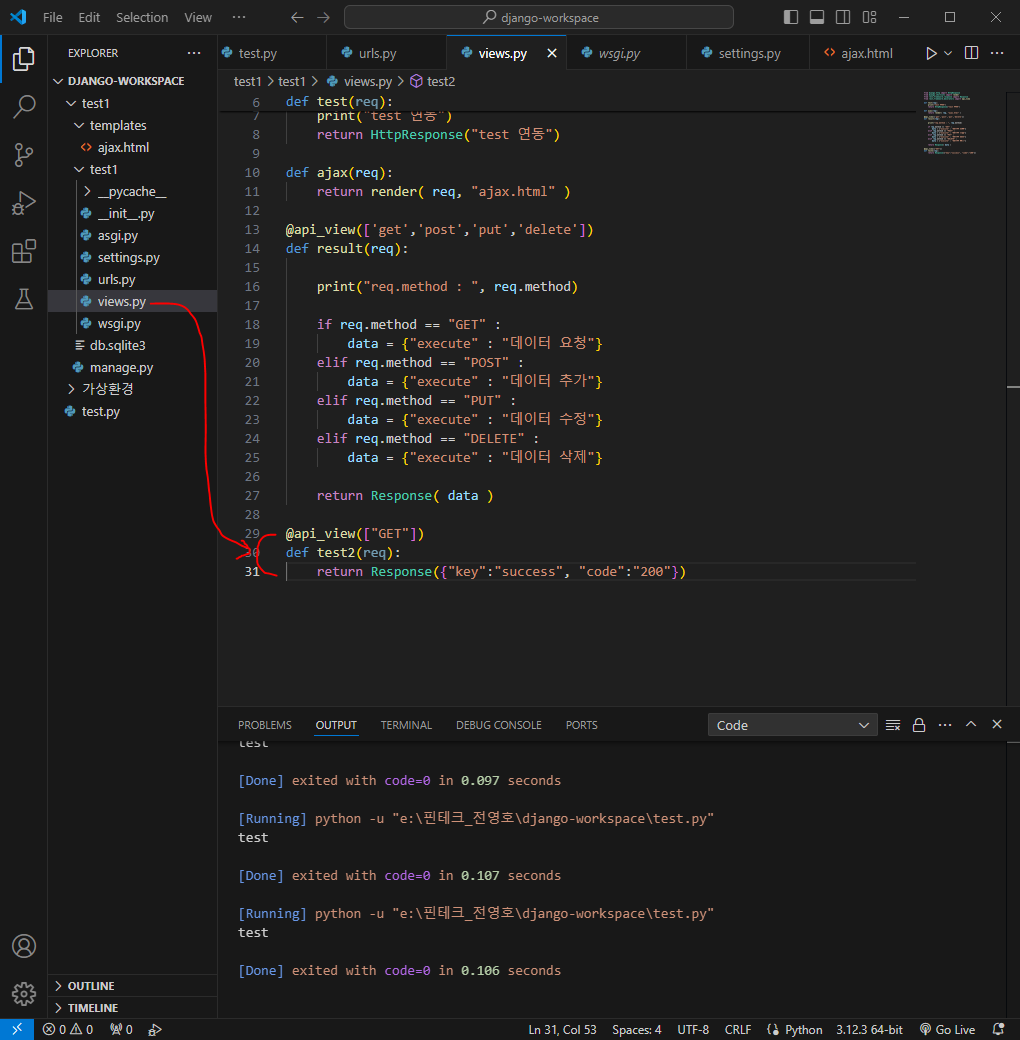
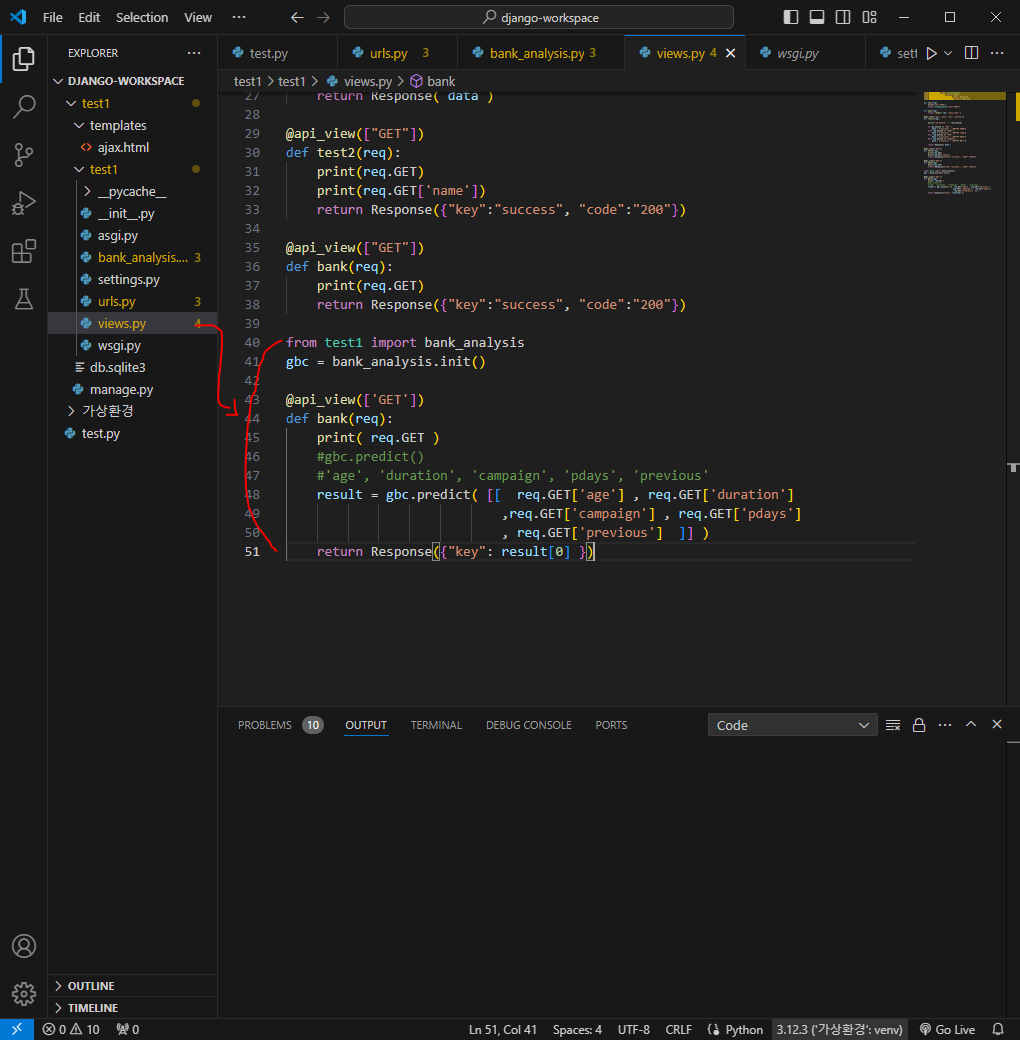
이제부터 데이터를 요청하고 응답하면 된다
대출이 가능한지 가능하지 않은지 확인하는 부분을 구현해볼 것임
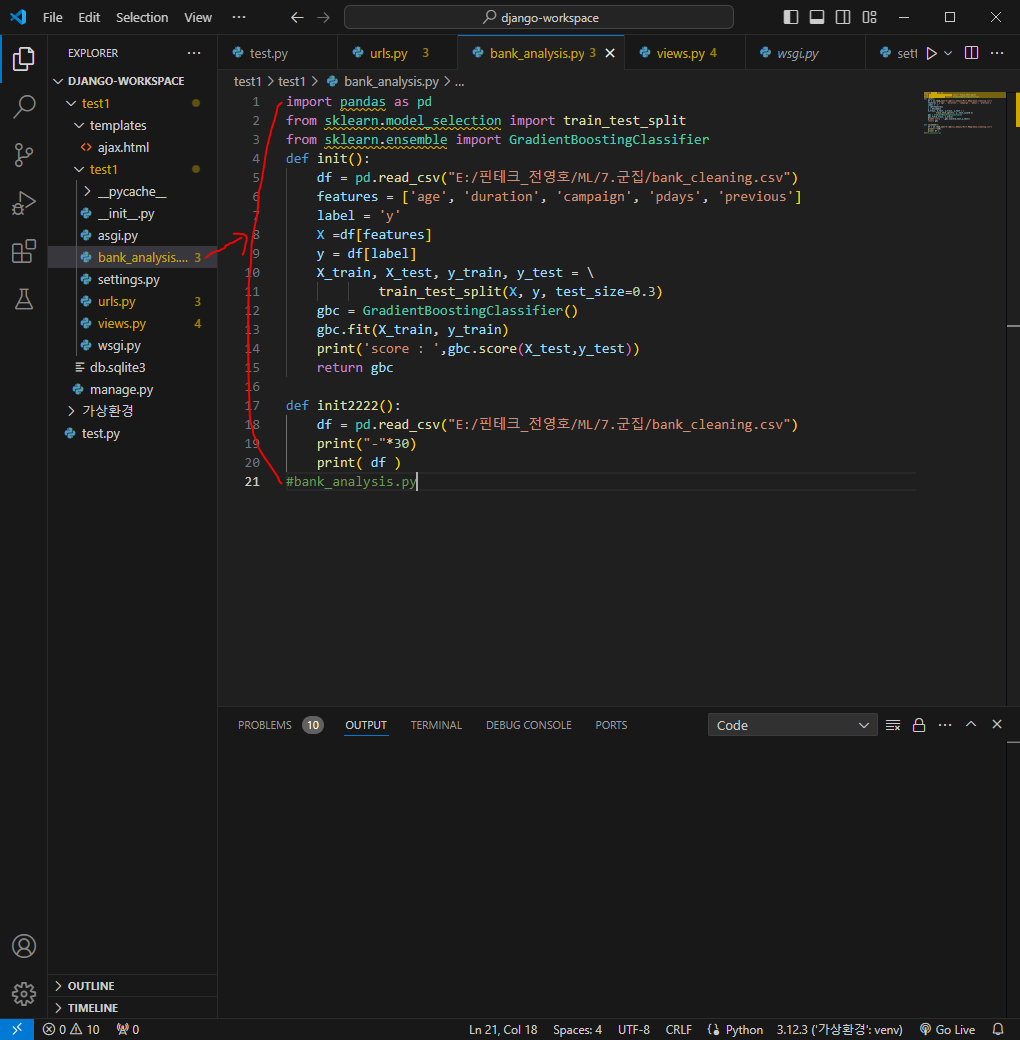
이제 스프링 코드 작성
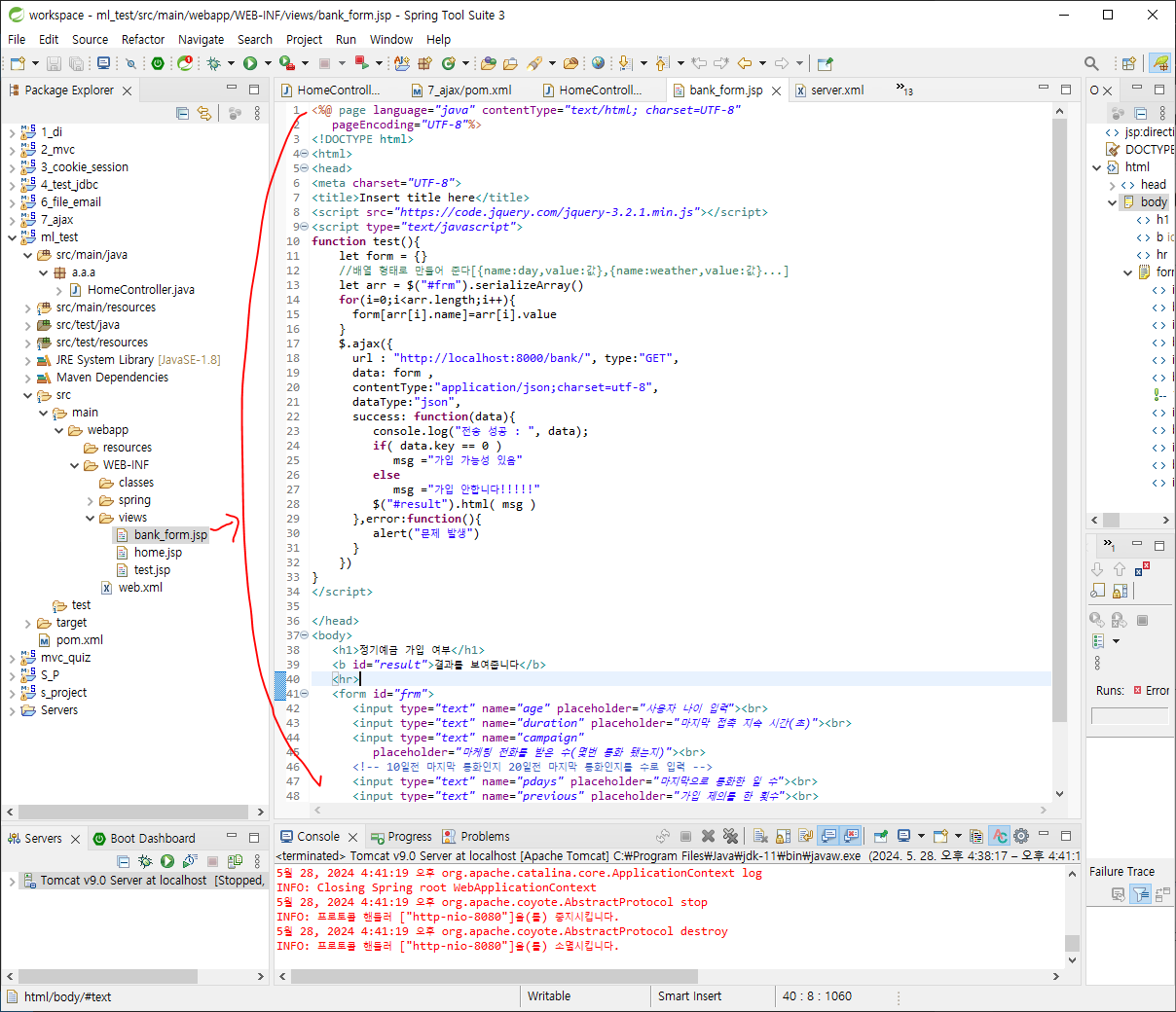
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
<script src="https://code.jquery.com/jquery-3.2.1.min.js"></script>
<script type="text/javascript">
function test(){
let form = {}
//배열 형태로 만들어 준다[{name:day,value:값},{name:weather,value:값}...]
let arr = $("#frm").serializeArray()
for(i=0;i<arr.length;i++){
form[arr[i].name]=arr[i].value
}
$.ajax({
url : "http://localhost:8000/bank/", type:"GET",
data: form ,
contentType:"application/json;charset=utf-8",
dataType:"json",
success: function(data){
console.log("전송 성공 : ", data);
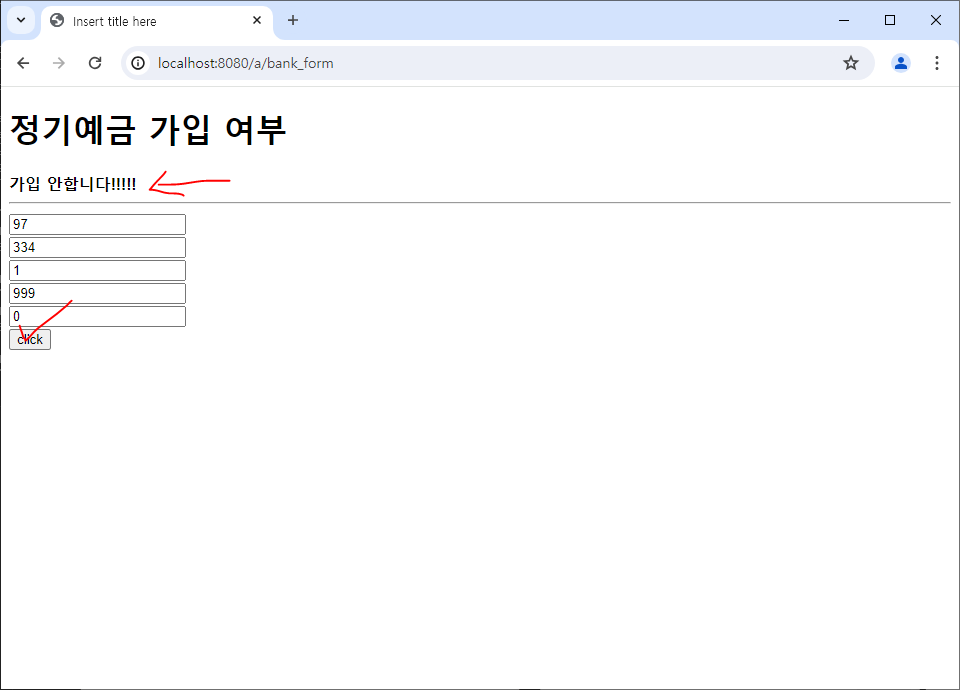
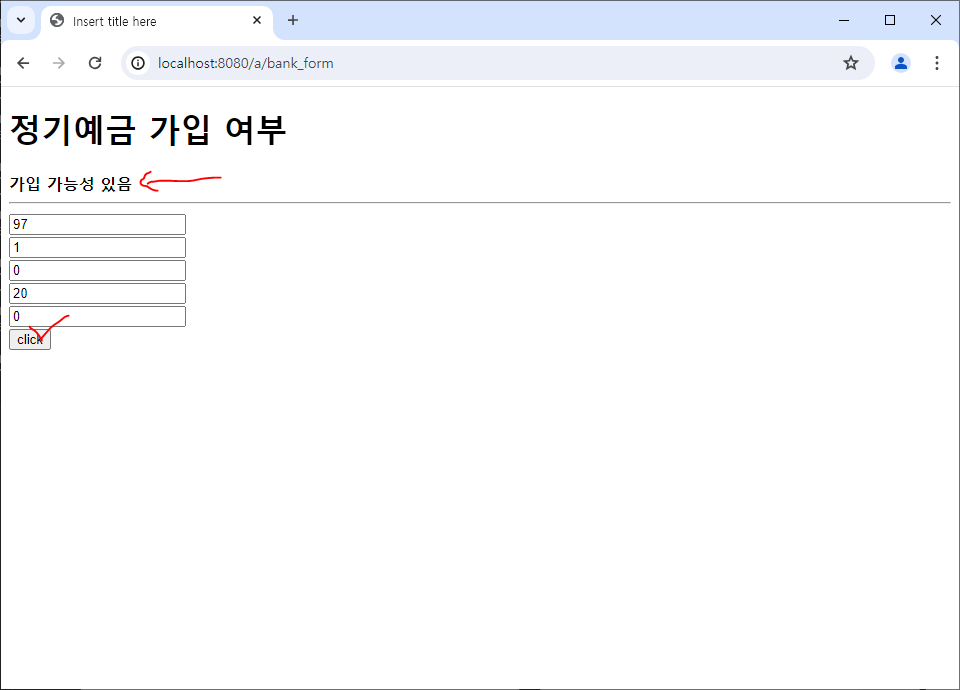
if( data.key == 0 )
msg ="가입 가능성 있음"
else
msg ="가입 안합니다!!!!!"
$("#result").html( msg )
},error:function(){
alert("문제 발생")
}
})
}
</script>
</head>
<body>
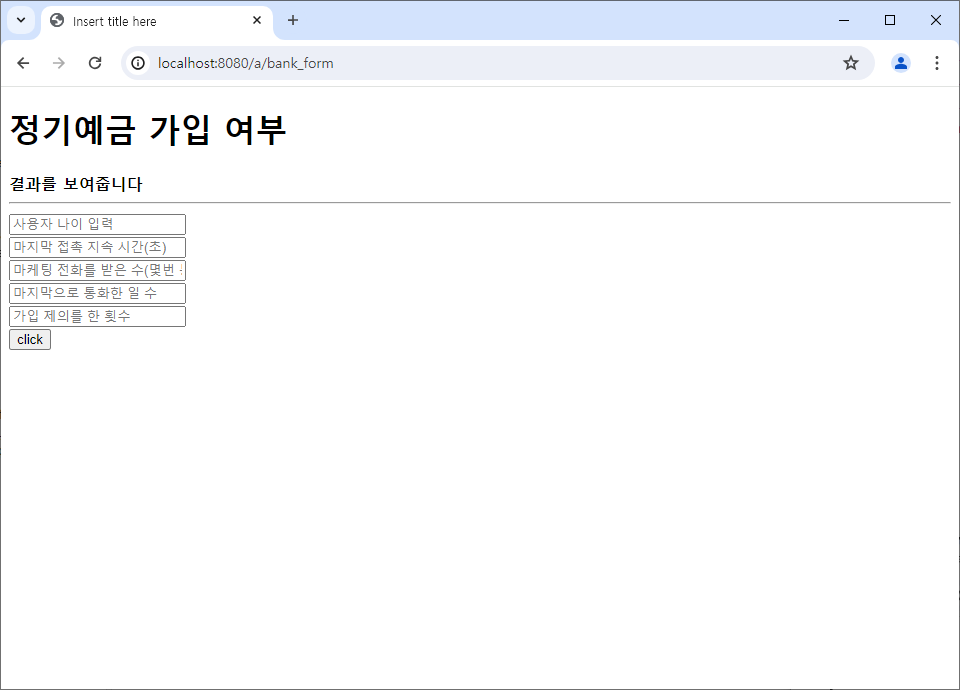
<h1>정기예금 가입 여부</h1>
<b id="result">결과를 보여줍니다</b>
<hr>
<form id="frm">
<input type="text" name="age" placeholder="사용자 나이 입력"><br>
<input type="text" name="duration" placeholder="마지막 접촉 지속 시간(초)"><br>
<input type="text" name="campaign"
placeholder="마케팅 전화를 받은 수(몇번 통화 됐는지)"><br>
<!-- 10일전 마지막 통화인지 20일전 마지막 통화인지를 수로 입력 -->
<input type="text" name="pdays" placeholder="마지막으로 통화한 일 수"><br>
<input type="text" name="previous" placeholder="가입 제의를 한 횟수"><br>
<input type="button" onclick="test()" value="click">
</form>
</body>
</html>
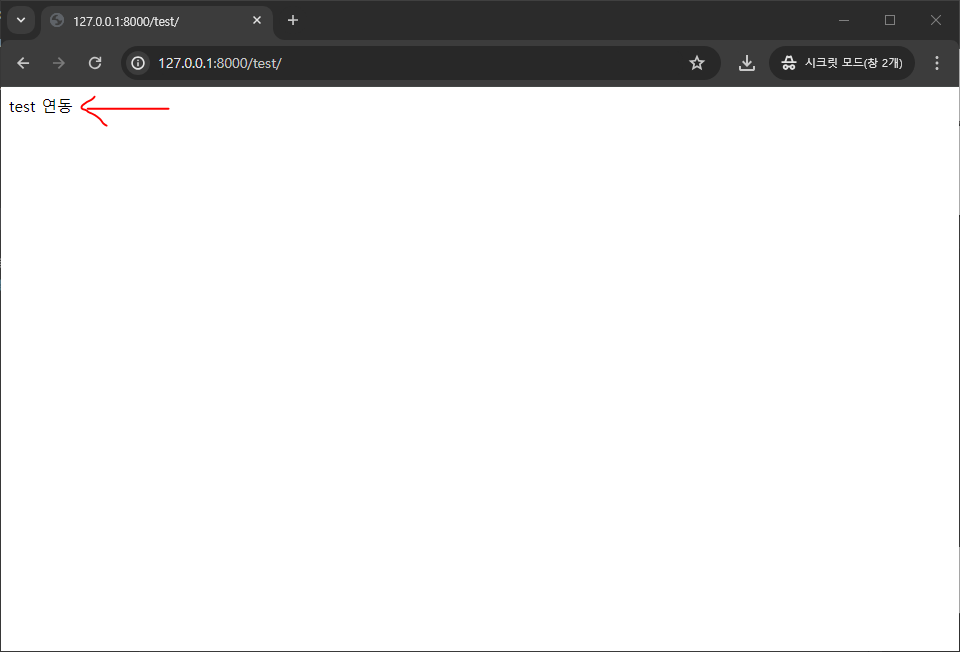
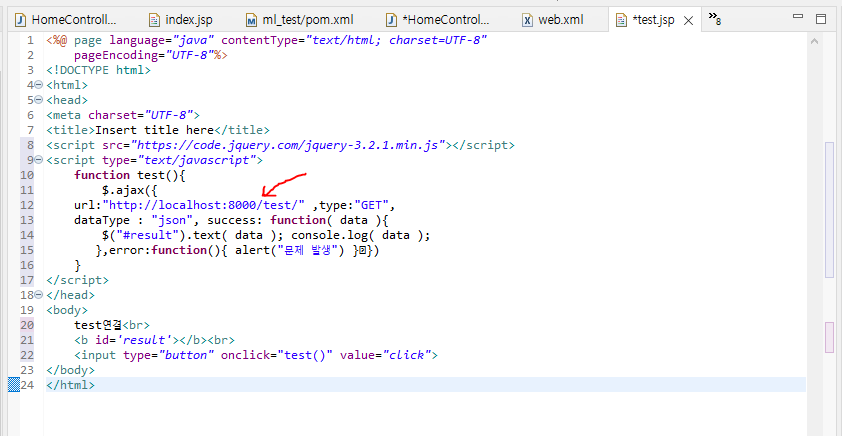
spring 서버 실행 후 경로 접속
▼ 세부 코드 ▼
ml_test.zip
0.02MB
test_1.zip
0.02MB
ml_test : spring 파일
test_1 : vscode 파일 ( python )
728x90
[머신러닝] 군집 ( 고객분류 )
2024. 5. 28. 11:42
군집 ( 고객분류 )
1.군집(고객분류).ipynb
0.29MB
1.군집(고객분류).html
0.56MB
군집(clustering)¶
- 레이블이 없는 데이터에 레이블을 부여하고자 할때 사용
- 비지도 학습으로 유사한 정도에 따라 다수의 객체를 그룹으로 만들때 사용
- 군집을 통해 레이블을 선정하여 지도학습으로 변경
- 군집의 개수 지정하는 방법
- 감으로(해당 그룹의 개수를 미리 알고 있는 경우)
- 평가지표로 확인(실루엣 지표 적용( -1 ~ 1사이, 1에 가까울수록 좋다)
- 그래프 그려서 눈으로 확인
k-means¶
- k-means은 군집화(clustering)에서 가장 일반적으로 사용되는 알고리즘
- 거리기반 군집화다. 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
k-means 파라미터¶
- n_clusters : 가장 중요한 파라미터로 군집화할 개수를 정의한다.
- init : 초기에 군집 중심점의 좌표를 설정할 방식을 말하며 일반적으로 k-means++방식으로 최초 설정한다
- k-means++ : 군집하기위한 중심좌표를 찍는 방식이며, 데이터 중 하나를 무작위로 선정후 다음번에는 가장 먼 곳을 중심으로 잡고 진행하는 방식
- max_iter : 최대 반복 횟수이며, 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료한다.
군집화가 완료되면 관련 주요 속성이 있다¶
- labels_ : 정답을 가지고 있는 변수(군집의 번호)
- cluster_centers_ : 각 군집 중심점 좌표(shape는[군집 개수, 피처 개수]), 이를 이용하면 군집 중심점 좌표가 어디인지 시각화 할 수 있다.
고객분류¶
고객들의 정보들을 가지고 있는 데이터 셋이다. 해당 데이터 셋을 이용하여 사용금액에 따른 고객을 분류하고자 한다.
분류 대상 : 연간 소득 대비 지출 점수를 통한 분류
컬럼
- CustomerID : 고객 아이디
- Gender : 성별
- Age : 나이
- Annual Income (k$) : 연간소득
- Spending Score (1-100) : 지출 점수
참고 - 필요한 컬럼은 연간 소득과 지출 점수만 있으면 된다.
In [1]:
# 군집이란?
# 군집은 비지도학습.... 정답이 없는 것들... data 들만 있는 것들을
# 그룹핑하는 작업
# 그룹핑을 해두어 새로운 데이터가 들어왔을때 해당되는 그룹으로 분류할 수 있다
In [2]:
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
In [3]:
df = pd.read_csv("../data_set/7.군집/Mall_Customers.csv")
df.head()
Out[3]:
| CustomerID | Gender | Age | Annual Income (k$) | Spending Score (1-100) | |
|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 |
| 1 | 2 | Male | 21 | 15 | 81 |
| 2 | 3 | Female | 20 | 16 | 6 |
| 3 | 4 | Female | 23 | 16 | 77 |
| 4 | 5 | Female | 31 | 17 | 40 |
In [4]:
# 시각화 해주는 라이브러리 추가
!pip install yellowbrick
Requirement already satisfied: yellowbrick in c:\users\user\appdata\roaming\python\python311\site-packages (1.5) Requirement already satisfied: matplotlib!=3.0.0,>=2.0.2 in c:\users\user\anaconda3\lib\site-packages (from yellowbrick) (3.8.0) Requirement already satisfied: scipy>=1.0.0 in c:\users\user\anaconda3\lib\site-packages (from yellowbrick) (1.11.4) Requirement already satisfied: scikit-learn>=1.0.0 in c:\users\user\anaconda3\lib\site-packages (from yellowbrick) (1.2.2) Requirement already satisfied: numpy>=1.16.0 in c:\users\user\anaconda3\lib\site-packages (from yellowbrick) (1.26.4) Requirement already satisfied: cycler>=0.10.0 in c:\users\user\anaconda3\lib\site-packages (from yellowbrick) (0.11.0) Requirement already satisfied: contourpy>=1.0.1 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (1.2.0) Requirement already satisfied: fonttools>=4.22.0 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (4.25.0) Requirement already satisfied: kiwisolver>=1.0.1 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (1.4.4) Requirement already satisfied: packaging>=20.0 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (23.1) Requirement already satisfied: pillow>=6.2.0 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (10.2.0) Requirement already satisfied: pyparsing>=2.3.1 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (3.0.9) Requirement already satisfied: python-dateutil>=2.7 in c:\users\user\anaconda3\lib\site-packages (from matplotlib!=3.0.0,>=2.0.2->yellowbrick) (2.8.2) Requirement already satisfied: joblib>=1.1.1 in c:\users\user\anaconda3\lib\site-packages (from scikit-learn>=1.0.0->yellowbrick) (1.2.0) Requirement already satisfied: threadpoolctl>=2.0.0 in c:\users\user\appdata\roaming\python\python311\site-packages (from scikit-learn>=1.0.0->yellowbrick) (3.1.0) Requirement already satisfied: six>=1.5 in c:\users\user\anaconda3\lib\site-packages (from python-dateutil>=2.7->matplotlib!=3.0.0,>=2.0.2->yellowbrick) (1.16.0)
In [5]:
df.columns
Out[5]:
Index(['CustomerID', 'Gender', 'Age', 'Annual Income (k$)',
'Spending Score (1-100)'],
dtype='object')
In [18]:
from yellowbrick.cluster import KElbowVisualizer
features = ['Annual Income (k$)', 'Spending Score (1-100)']
model = KMeans()
vis = KElbowVisualizer(model, k=(1, 10))
# 군집에 대한 갯수를 1 ~ 10 개의 그룹으로 지정
# 그 중에 맞는 것으로 설정
vis.fit(df[features])
vis.show()
# 검은 점선이 있는 4 가 군집의 적당한 수이다
# 4개의 집단으로 분류했을때가 가장 적합하다...!

Out[18]:
<Axes: title={'center': 'Distortion Score Elbow for KMeans Clustering'}, xlabel='k', ylabel='distortion score'>
In [ ]:
In [ ]:
In [13]:
from sklearn.metrics import silhouette_score
all_scores = []
i=2
while i<10:
i+=1
km = KMeans(n_clusters=i)
km.fit( df[features] )
sil_score = silhouette_score(df[features], km.labels_)
dic = {"cluster_num" : i, "score" : sil_score}
all_scores.append(dic)
s_df = pd.DataFrame(all_scores)
In [17]:
# score 를 기준으로 오름차순으로 정렬
s_df.sort_values(by="score")
# 5개의 집단으로 분류했을때가 가장 적합하다...!
Out[17]:
| cluster_num | score | |
|---|---|---|
| 7 | 10 | 0.452751 |
| 5 | 8 | 0.454558 |
| 6 | 9 | 0.458196 |
| 0 | 3 | 0.467614 |
| 1 | 4 | 0.493196 |
| 4 | 7 | 0.528810 |
| 3 | 6 | 0.539761 |
| 2 | 5 | 0.553932 |
In [19]:
set(km.labels_)
Out[19]:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
In [20]:
km = KMeans(n_clusters=5, init="k-means++", max_iter=300)
# 300 번 반복하면서 최적의 중심점을 찾겠다
# n_clusters = 5 : 5 개의 그룹으로 묶겠다
km.fit(df[features])
Out[20]:
KMeans(n_clusters=5)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KMeans(n_clusters=5)
In [21]:
set(km.labels_)
Out[21]:
{0, 1, 2, 3, 4}
In [25]:
# cluster 컬럼을 생성하여 각 데이터가 속한
# 그룹을 표현
df['cluster'] = km.labels_
df
Out[25]:
| CustomerID | Gender | Age | Annual Income (k$) | Spending Score (1-100) | cluster | |
|---|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 | 2 |
| 1 | 2 | Male | 21 | 15 | 81 | 1 |
| 2 | 3 | Female | 20 | 16 | 6 | 2 |
| 3 | 4 | Female | 23 | 16 | 77 | 1 |
| 4 | 5 | Female | 31 | 17 | 40 | 2 |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 | 4 |
| 196 | 197 | Female | 45 | 126 | 28 | 3 |
| 197 | 198 | Male | 32 | 126 | 74 | 4 |
| 198 | 199 | Male | 32 | 137 | 18 | 3 |
| 199 | 200 | Male | 30 | 137 | 83 | 4 |
200 rows × 6 columns
In [27]:
# 군집을 통해 분류한 것을 시각화
f = ['Annual Income (k$)', 'Spending Score (1-100)', 'cluster']
plt.figure(figsize=(12,8))
sns.scatterplot( data = df[f], x="Annual Income (k$)", y="Spending Score (1-100)", hue="cluster" )
Out[27]:
<Axes: xlabel='Annual Income (k$)', ylabel='Spending Score (1-100)'>

In [ ]:
In [ ]:
In [29]:
# 중심좌표를 알려주는 cluster_centers_
# 각 군집마다 중심 좌표를 알려준다
km.cluster_centers_
Out[29]:
array([[55.2962963 , 49.51851852],
[25.72727273, 79.36363636],
[26.30434783, 20.91304348],
[88.2 , 17.11428571],
[86.53846154, 82.12820513]])
In [31]:
cnt = km.cluster_centers_
cnt[:,0]
Out[31]:
array([55.2962963 , 25.72727273, 26.30434783, 88.2 , 86.53846154])
In [32]:
cnt[:,1]
Out[32]:
array([49.51851852, 79.36363636, 20.91304348, 17.11428571, 82.12820513])
In [37]:
# 군집 별 중심좌표를 시각화
plt.scatter(x=cnt[:,0], y=cnt[:,1], c="red", s=200)
# c : 표시될 점의 색깔
# s : 표시될 점의 크기
Out[37]:
<matplotlib.collections.PathCollection at 0x1539bbc9210>

In [39]:
# 군집의 표본과 중심좌표를 동시에 시각화
plt.figure(figsize=(12,8))
sns.scatterplot( data = df[f], x="Annual Income (k$)", y="Spending Score (1-100)", hue="cluster" )
plt.scatter(x=cnt[:,0], y=cnt[:,1], c="red", s=200)
Out[39]:
<matplotlib.collections.PathCollection at 0x15398c23650>

In [ ]:
In [ ]:
In [40]:
fe = ['Annual Income (k$)', 'Spending Score (1-100)']
label = "cluster"
In [41]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df[fe], df[label], test_size=0.3)
In [46]:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 새로운 데이터가 들어오면 몇번 그룹인지 분류하기 위해
# RandomForestClassifier 를 사용
params = {
"n_estimators" : range(5,100,10),
"max_depth" : range(4,11,2),
"min_samples_leaf" : range(5,21,5)
}
In [47]:
rfc = RandomForestClassifier()
grid_cv = GridSearchCV(rfc, param_grid=params, cv=3, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print("최적의 파라미터 : ", grid_cv.best_params_)
print("train : ", grid_cv.score(X_train, y_train))
print("test : ", grid_cv.score(X_test, y_test))
최적의 파라미터 : {'max_depth': 4, 'min_samples_leaf': 5, 'n_estimators': 25}
train : 0.9928571428571429
test : 0.9333333333333333
In [49]:
# 새로운 데이터를 집어넣으면 몇번째 그룹에 해당하는 데이터인지
# 분류해준다
grid_cv.predict([[20,20]])
Out[49]:
array([2])
728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 변수 선택법 ( feature selection ) (0) | 2024.05.28 |
|---|---|
| [머신러닝] 회귀 및 평가지표 (0) | 2024.05.27 |
| [머신러닝] 과적합 및 하이퍼파라미터 (0) | 2024.05.27 |
| [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 (0) | 2024.05.24 |
| [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) (0) | 2024.05.24 |
[머신러닝] 변수 선택법 ( feature selection )
2024. 5. 28. 10:43
변수 선택법 ( feature selection )
2. feature selection(변수 선택법).ipynb
1.50MB
2. feature selection(변수 선택법).html
1.78MB
feature selection(변수 선택법)¶
필요한 변수만 선택하여 모델의 예측력을 높이거나 과적합을 줄이는 것
알고리즘의 정확도가 유사하다면 변수의 개수가 적을수록 속도가 빠르다
방법
- 단변량(filter) : 특정 컬럼이 또 다른 컬럼과 상관관계가 있는지 확인하는 방법
- 전진/후진 선택법(wrapper) : 컬럼을 하나씩 추가하며 점수 확인 / 하나씩 빼며 점수 확인
- RFE : 사이킷런에서 제공하는 라이브러리를 이용하여 변수의 중요도를 확인하여 변수를 선택하는 방법
- embed(임베드) : 알고리즘의 성질 이용
- 알고리즘 내부에서 각 feature 구송 요소들이 얼마나 사용 되었는지를 알아보는 방식
- 알고리즘들을 이용해 변수의 중요도를 파악, 중요도 낮은 컬럼은 지울 수 있다
- 참고
- RFE와 embed 방식은 특정 알고리즘에 존재하며, 해당 방식을 사용할 수 없는 알고리즘들이 존재한다.(KNN, SVR(kernel=rbf)등 사용 못함)
- Tree계열 알고리즘들은 사용 가능하다(Random Forest, Decision Tree 등)
In [ ]:
# 단변량 : 비슷한 컬럼들을 확인 후 제거하는 것
# embed : Tree 계열 알고리즘에서만 사용 가능, 각 컬럼의 티어를 알려준다.
In [1]:
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
df = pd.read_csv("../data_set/6.회귀/data_cleaning.csv")
df.head()
Out[1]:
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | day | hour | temp_int | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011 | 1 | 1 | 0 | 9 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011 | 1 | 1 | 1 | 9 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011 | 1 | 1 | 2 | 9 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011 | 1 | 1 | 3 | 9 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011 | 1 | 1 | 4 | 9 |
In [2]:
df.columns
Out[2]:
Index(['datetime', 'season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count',
'year', 'month', 'day', 'hour', 'temp_int'],
dtype='object')
In [3]:
f = ['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'year', 'month', 'day', 'hour']
l = "count"
X, y = df[f], df[l]
In [4]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
In [5]:
model = RandomForestRegressor()
model.fit(X_train, y_train)
print("train : ", model.score(X_train, y_train))
print("test : ", model.score(X_test, y_test))
train : 0.9916614979489478 test : 0.9410126086888452
In [14]:
# 서로의 상관관계가 높을 수록 그래프가 일정하게 상승 또는 하강한다
import seaborn as sns
sns.scatterplot(data=df, x="temp", y="atemp")
Out[14]:
<Axes: xlabel='temp', ylabel='atemp'>

In [11]:
# 각 컬럼 간의 상관관계를 보여준다
# temp 와 atemp 의 상관관계가 1에 가깝기 때문에
# 제거해도 될듯 하다
df.corr(numeric_only=True)
Out[11]:
| season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | day | hour | temp_int | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| season | 1.000000 | 0.029368 | -0.008126 | 0.008879 | 0.258689 | 0.264744 | 0.190610 | -0.147121 | 0.096758 | 0.164011 | 0.163439 | -0.004797 | 0.971524 | 0.001729 | -0.006546 | 0.257917 |
| holiday | 0.029368 | 1.000000 | -0.250491 | -0.007074 | 0.000295 | -0.005215 | 0.001929 | 0.008409 | 0.043799 | -0.020956 | -0.005393 | 0.012021 | 0.001731 | -0.015877 | -0.000354 | 0.000192 |
| workingday | -0.008126 | -0.250491 | 1.000000 | 0.033772 | 0.029966 | 0.024660 | -0.010880 | 0.013373 | -0.319111 | 0.119460 | 0.011594 | -0.002482 | -0.003394 | 0.009829 | 0.002780 | 0.029603 |
| weather | 0.008879 | -0.007074 | 0.033772 | 1.000000 | -0.055035 | -0.055376 | 0.406244 | 0.007261 | -0.135918 | -0.109340 | -0.128655 | -0.012548 | 0.012144 | -0.007890 | -0.022740 | -0.054556 |
| temp | 0.258689 | 0.000295 | 0.029966 | -0.055035 | 1.000000 | 0.984948 | -0.064949 | -0.017852 | 0.467097 | 0.318571 | 0.394454 | 0.061226 | 0.257589 | 0.015551 | 0.145430 | 0.999313 |
| atemp | 0.264744 | -0.005215 | 0.024660 | -0.055376 | 0.984948 | 1.000000 | -0.043536 | -0.057473 | 0.462067 | 0.314635 | 0.389784 | 0.058540 | 0.264173 | 0.011866 | 0.140343 | 0.984431 |
| humidity | 0.190610 | 0.001929 | -0.010880 | 0.406244 | -0.064949 | -0.043536 | 1.000000 | -0.318607 | -0.348187 | -0.265458 | -0.317371 | -0.078606 | 0.204537 | -0.011335 | -0.278011 | -0.064205 |
| windspeed | -0.147121 | 0.008409 | 0.013373 | 0.007261 | -0.017852 | -0.057473 | -0.318607 | 1.000000 | 0.092276 | 0.091052 | 0.101369 | -0.015221 | -0.150192 | 0.036157 | 0.146631 | -0.017660 |
| casual | 0.096758 | 0.043799 | -0.319111 | -0.135918 | 0.467097 | 0.462067 | -0.348187 | 0.092276 | 1.000000 | 0.497250 | 0.690414 | 0.145241 | 0.092722 | 0.014109 | 0.302045 | 0.467047 |
| registered | 0.164011 | -0.020956 | 0.119460 | -0.109340 | 0.318571 | 0.314635 | -0.265458 | 0.091052 | 0.497250 | 1.000000 | 0.970948 | 0.264265 | 0.169451 | 0.019111 | 0.380540 | 0.318048 |
| count | 0.163439 | -0.005393 | 0.011594 | -0.128655 | 0.394454 | 0.389784 | -0.317371 | 0.101369 | 0.690414 | 0.970948 | 1.000000 | 0.260403 | 0.166862 | 0.019826 | 0.400601 | 0.394003 |
| year | -0.004797 | 0.012021 | -0.002482 | -0.012548 | 0.061226 | 0.058540 | -0.078606 | -0.015221 | 0.145241 | 0.264265 | 0.260403 | 1.000000 | -0.004932 | 0.001800 | -0.004234 | 0.060692 |
| month | 0.971524 | 0.001731 | -0.003394 | 0.012144 | 0.257589 | 0.264173 | 0.204537 | -0.150192 | 0.092722 | 0.169451 | 0.166862 | -0.004932 | 1.000000 | 0.001974 | -0.006818 | 0.256862 |
| day | 0.001729 | -0.015877 | 0.009829 | -0.007890 | 0.015551 | 0.011866 | -0.011335 | 0.036157 | 0.014109 | 0.019111 | 0.019826 | 0.001800 | 0.001974 | 1.000000 | 0.001132 | 0.016202 |
| hour | -0.006546 | -0.000354 | 0.002780 | -0.022740 | 0.145430 | 0.140343 | -0.278011 | 0.146631 | 0.302045 | 0.380540 | 0.400601 | -0.004234 | -0.006818 | 0.001132 | 1.000000 | 0.145353 |
| temp_int | 0.257917 | 0.000192 | 0.029603 | -0.054556 | 0.999313 | 0.984431 | -0.064205 | -0.017660 | 0.467047 | 0.318048 | 0.394003 | 0.060692 | 0.256862 | 0.016202 | 0.145353 | 1.000000 |
In [13]:
import matplotlib.pyplot as plt
plt.subplots(figsize=(12,12))
sns.heatmap(df.corr(numeric_only=True), annot=True)
Out[13]:
<Axes: >

In [16]:
# 상관관계가 비슷한 것들은 / 이 형태나 \ 이 형태로 값이
# 일정하게 줄어들거나 늘어난다
sns.pairplot(df, height=1)
Out[16]:
<seaborn.axisgrid.PairGrid at 0x16a895c6710>

In [18]:
# atemp 삭제
f = ['season', 'holiday', 'workingday', 'weather', 'temp',
'humidity', 'windspeed', 'year', 'month', 'day', 'hour']
# atemp 컬럼을 삭제해도 예측 결과 값에는 영향을 크게 끼치지 않았음
# atemp 와 temp 가 거의 동일한 컬럼이었기 때문...!
X_train, X_test, y_train, y_test = train_test_split(df[f], df[l], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
print("train : ", model.score(X_train, y_train))
print("test : ", model.score(X_test, y_test))
train : 0.9917278017758199 test : 0.9399504472888517
In [ ]:
In [ ]:
wrapper(전진/후진 선택)¶
- feature를 추가 / 제거하면서 모델의 성능을 확인한다
- combinations : 모든 값들의 경우의 수를 뽑아준다
In [22]:
from itertools import combinations
sample_bag = [1,2,3,4]
for c in combinations(sample_bag, 2) :
# sample_bag 를 2개씩 뽑으라는 뜻
print(c, type(c))
(1, 2) <class 'tuple'> (1, 3) <class 'tuple'> (1, 4) <class 'tuple'> (2, 3) <class 'tuple'> (2, 4) <class 'tuple'> (3, 4) <class 'tuple'>
In [25]:
all_result = []
# combinations() 가 컬럼들을 2개씩 묶어준다
for c in combinations(f, 2):
print(c)
('season', 'holiday')
('season', 'workingday')
('season', 'weather')
('season', 'temp')
('season', 'humidity')
('season', 'windspeed')
('season', 'year')
('season', 'month')
('season', 'day')
('season', 'hour')
('holiday', 'workingday')
('holiday', 'weather')
('holiday', 'temp')
('holiday', 'humidity')
('holiday', 'windspeed')
('holiday', 'year')
('holiday', 'month')
('holiday', 'day')
('holiday', 'hour')
('workingday', 'weather')
('workingday', 'temp')
('workingday', 'humidity')
('workingday', 'windspeed')
('workingday', 'year')
('workingday', 'month')
('workingday', 'day')
('workingday', 'hour')
('weather', 'temp')
('weather', 'humidity')
('weather', 'windspeed')
('weather', 'year')
('weather', 'month')
('weather', 'day')
('weather', 'hour')
('temp', 'humidity')
('temp', 'windspeed')
('temp', 'year')
('temp', 'month')
('temp', 'day')
('temp', 'hour')
('humidity', 'windspeed')
('humidity', 'year')
('humidity', 'month')
('humidity', 'day')
('humidity', 'hour')
('windspeed', 'year')
('windspeed', 'month')
('windspeed', 'day')
('windspeed', 'hour')
('year', 'month')
('year', 'day')
('year', 'hour')
('month', 'day')
('month', 'hour')
('day', 'hour')
In [27]:
for c in combinations(f, 2):
# 컬럼을 list 자료형으로 형변환해서 사용해야 한다
print( df[list(c)] )
season holiday
0 1 0
1 1 0
2 1 0
3 1 0
4 1 0
... ... ...
10881 4 0
10882 4 0
10883 4 0
10884 4 0
10885 4 0
[10886 rows x 2 columns]
season workingday
0 1 0
1 1 0
2 1 0
3 1 0
4 1 0
... ... ...
10881 4 1
10882 4 1
10883 4 1
10884 4 1
10885 4 1
[10886 rows x 2 columns]
season weather
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 4 1
10882 4 1
10883 4 1
10884 4 1
10885 4 1
[10886 rows x 2 columns]
season temp
0 1 9.84
1 1 9.02
2 1 9.02
3 1 9.84
4 1 9.84
... ... ...
10881 4 15.58
10882 4 14.76
10883 4 13.94
10884 4 13.94
10885 4 13.12
[10886 rows x 2 columns]
season humidity
0 1 81
1 1 80
2 1 80
3 1 75
4 1 75
... ... ...
10881 4 50
10882 4 57
10883 4 61
10884 4 61
10885 4 66
[10886 rows x 2 columns]
season windspeed
0 1 0.0000
1 1 0.0000
2 1 0.0000
3 1 0.0000
4 1 0.0000
... ... ...
10881 4 26.0027
10882 4 15.0013
10883 4 15.0013
10884 4 6.0032
10885 4 8.9981
[10886 rows x 2 columns]
season year
0 1 2011
1 1 2011
2 1 2011
3 1 2011
4 1 2011
... ... ...
10881 4 2012
10882 4 2012
10883 4 2012
10884 4 2012
10885 4 2012
[10886 rows x 2 columns]
season month
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 4 12
10882 4 12
10883 4 12
10884 4 12
10885 4 12
[10886 rows x 2 columns]
season day
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 4 19
10882 4 19
10883 4 19
10884 4 19
10885 4 19
[10886 rows x 2 columns]
season hour
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
... ... ...
10881 4 19
10882 4 20
10883 4 21
10884 4 22
10885 4 23
[10886 rows x 2 columns]
holiday workingday
0 0 0
1 0 0
2 0 0
3 0 0
4 0 0
... ... ...
10881 0 1
10882 0 1
10883 0 1
10884 0 1
10885 0 1
[10886 rows x 2 columns]
holiday weather
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 0 1
10882 0 1
10883 0 1
10884 0 1
10885 0 1
[10886 rows x 2 columns]
holiday temp
0 0 9.84
1 0 9.02
2 0 9.02
3 0 9.84
4 0 9.84
... ... ...
10881 0 15.58
10882 0 14.76
10883 0 13.94
10884 0 13.94
10885 0 13.12
[10886 rows x 2 columns]
holiday humidity
0 0 81
1 0 80
2 0 80
3 0 75
4 0 75
... ... ...
10881 0 50
10882 0 57
10883 0 61
10884 0 61
10885 0 66
[10886 rows x 2 columns]
holiday windspeed
0 0 0.0000
1 0 0.0000
2 0 0.0000
3 0 0.0000
4 0 0.0000
... ... ...
10881 0 26.0027
10882 0 15.0013
10883 0 15.0013
10884 0 6.0032
10885 0 8.9981
[10886 rows x 2 columns]
holiday year
0 0 2011
1 0 2011
2 0 2011
3 0 2011
4 0 2011
... ... ...
10881 0 2012
10882 0 2012
10883 0 2012
10884 0 2012
10885 0 2012
[10886 rows x 2 columns]
holiday month
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 0 12
10882 0 12
10883 0 12
10884 0 12
10885 0 12
[10886 rows x 2 columns]
holiday day
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 0 19
10882 0 19
10883 0 19
10884 0 19
10885 0 19
[10886 rows x 2 columns]
holiday hour
0 0 0
1 0 1
2 0 2
3 0 3
4 0 4
... ... ...
10881 0 19
10882 0 20
10883 0 21
10884 0 22
10885 0 23
[10886 rows x 2 columns]
workingday weather
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 1 1
10882 1 1
10883 1 1
10884 1 1
10885 1 1
[10886 rows x 2 columns]
workingday temp
0 0 9.84
1 0 9.02
2 0 9.02
3 0 9.84
4 0 9.84
... ... ...
10881 1 15.58
10882 1 14.76
10883 1 13.94
10884 1 13.94
10885 1 13.12
[10886 rows x 2 columns]
workingday humidity
0 0 81
1 0 80
2 0 80
3 0 75
4 0 75
... ... ...
10881 1 50
10882 1 57
10883 1 61
10884 1 61
10885 1 66
[10886 rows x 2 columns]
workingday windspeed
0 0 0.0000
1 0 0.0000
2 0 0.0000
3 0 0.0000
4 0 0.0000
... ... ...
10881 1 26.0027
10882 1 15.0013
10883 1 15.0013
10884 1 6.0032
10885 1 8.9981
[10886 rows x 2 columns]
workingday year
0 0 2011
1 0 2011
2 0 2011
3 0 2011
4 0 2011
... ... ...
10881 1 2012
10882 1 2012
10883 1 2012
10884 1 2012
10885 1 2012
[10886 rows x 2 columns]
workingday month
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 1 12
10882 1 12
10883 1 12
10884 1 12
10885 1 12
[10886 rows x 2 columns]
workingday day
0 0 1
1 0 1
2 0 1
3 0 1
4 0 1
... ... ...
10881 1 19
10882 1 19
10883 1 19
10884 1 19
10885 1 19
[10886 rows x 2 columns]
workingday hour
0 0 0
1 0 1
2 0 2
3 0 3
4 0 4
... ... ...
10881 1 19
10882 1 20
10883 1 21
10884 1 22
10885 1 23
[10886 rows x 2 columns]
weather temp
0 1 9.84
1 1 9.02
2 1 9.02
3 1 9.84
4 1 9.84
... ... ...
10881 1 15.58
10882 1 14.76
10883 1 13.94
10884 1 13.94
10885 1 13.12
[10886 rows x 2 columns]
weather humidity
0 1 81
1 1 80
2 1 80
3 1 75
4 1 75
... ... ...
10881 1 50
10882 1 57
10883 1 61
10884 1 61
10885 1 66
[10886 rows x 2 columns]
weather windspeed
0 1 0.0000
1 1 0.0000
2 1 0.0000
3 1 0.0000
4 1 0.0000
... ... ...
10881 1 26.0027
10882 1 15.0013
10883 1 15.0013
10884 1 6.0032
10885 1 8.9981
[10886 rows x 2 columns]
weather year
0 1 2011
1 1 2011
2 1 2011
3 1 2011
4 1 2011
... ... ...
10881 1 2012
10882 1 2012
10883 1 2012
10884 1 2012
10885 1 2012
[10886 rows x 2 columns]
weather month
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 1 12
10882 1 12
10883 1 12
10884 1 12
10885 1 12
[10886 rows x 2 columns]
weather day
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 1 19
10882 1 19
10883 1 19
10884 1 19
10885 1 19
[10886 rows x 2 columns]
weather hour
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
... ... ...
10881 1 19
10882 1 20
10883 1 21
10884 1 22
10885 1 23
[10886 rows x 2 columns]
temp humidity
0 9.84 81
1 9.02 80
2 9.02 80
3 9.84 75
4 9.84 75
... ... ...
10881 15.58 50
10882 14.76 57
10883 13.94 61
10884 13.94 61
10885 13.12 66
[10886 rows x 2 columns]
temp windspeed
0 9.84 0.0000
1 9.02 0.0000
2 9.02 0.0000
3 9.84 0.0000
4 9.84 0.0000
... ... ...
10881 15.58 26.0027
10882 14.76 15.0013
10883 13.94 15.0013
10884 13.94 6.0032
10885 13.12 8.9981
[10886 rows x 2 columns]
temp year
0 9.84 2011
1 9.02 2011
2 9.02 2011
3 9.84 2011
4 9.84 2011
... ... ...
10881 15.58 2012
10882 14.76 2012
10883 13.94 2012
10884 13.94 2012
10885 13.12 2012
[10886 rows x 2 columns]
temp month
0 9.84 1
1 9.02 1
2 9.02 1
3 9.84 1
4 9.84 1
... ... ...
10881 15.58 12
10882 14.76 12
10883 13.94 12
10884 13.94 12
10885 13.12 12
[10886 rows x 2 columns]
temp day
0 9.84 1
1 9.02 1
2 9.02 1
3 9.84 1
4 9.84 1
... ... ...
10881 15.58 19
10882 14.76 19
10883 13.94 19
10884 13.94 19
10885 13.12 19
[10886 rows x 2 columns]
temp hour
0 9.84 0
1 9.02 1
2 9.02 2
3 9.84 3
4 9.84 4
... ... ...
10881 15.58 19
10882 14.76 20
10883 13.94 21
10884 13.94 22
10885 13.12 23
[10886 rows x 2 columns]
humidity windspeed
0 81 0.0000
1 80 0.0000
2 80 0.0000
3 75 0.0000
4 75 0.0000
... ... ...
10881 50 26.0027
10882 57 15.0013
10883 61 15.0013
10884 61 6.0032
10885 66 8.9981
[10886 rows x 2 columns]
humidity year
0 81 2011
1 80 2011
2 80 2011
3 75 2011
4 75 2011
... ... ...
10881 50 2012
10882 57 2012
10883 61 2012
10884 61 2012
10885 66 2012
[10886 rows x 2 columns]
humidity month
0 81 1
1 80 1
2 80 1
3 75 1
4 75 1
... ... ...
10881 50 12
10882 57 12
10883 61 12
10884 61 12
10885 66 12
[10886 rows x 2 columns]
humidity day
0 81 1
1 80 1
2 80 1
3 75 1
4 75 1
... ... ...
10881 50 19
10882 57 19
10883 61 19
10884 61 19
10885 66 19
[10886 rows x 2 columns]
humidity hour
0 81 0
1 80 1
2 80 2
3 75 3
4 75 4
... ... ...
10881 50 19
10882 57 20
10883 61 21
10884 61 22
10885 66 23
[10886 rows x 2 columns]
windspeed year
0 0.0000 2011
1 0.0000 2011
2 0.0000 2011
3 0.0000 2011
4 0.0000 2011
... ... ...
10881 26.0027 2012
10882 15.0013 2012
10883 15.0013 2012
10884 6.0032 2012
10885 8.9981 2012
[10886 rows x 2 columns]
windspeed month
0 0.0000 1
1 0.0000 1
2 0.0000 1
3 0.0000 1
4 0.0000 1
... ... ...
10881 26.0027 12
10882 15.0013 12
10883 15.0013 12
10884 6.0032 12
10885 8.9981 12
[10886 rows x 2 columns]
windspeed day
0 0.0000 1
1 0.0000 1
2 0.0000 1
3 0.0000 1
4 0.0000 1
... ... ...
10881 26.0027 19
10882 15.0013 19
10883 15.0013 19
10884 6.0032 19
10885 8.9981 19
[10886 rows x 2 columns]
windspeed hour
0 0.0000 0
1 0.0000 1
2 0.0000 2
3 0.0000 3
4 0.0000 4
... ... ...
10881 26.0027 19
10882 15.0013 20
10883 15.0013 21
10884 6.0032 22
10885 8.9981 23
[10886 rows x 2 columns]
year month
0 2011 1
1 2011 1
2 2011 1
3 2011 1
4 2011 1
... ... ...
10881 2012 12
10882 2012 12
10883 2012 12
10884 2012 12
10885 2012 12
[10886 rows x 2 columns]
year day
0 2011 1
1 2011 1
2 2011 1
3 2011 1
4 2011 1
... ... ...
10881 2012 19
10882 2012 19
10883 2012 19
10884 2012 19
10885 2012 19
[10886 rows x 2 columns]
year hour
0 2011 0
1 2011 1
2 2011 2
3 2011 3
4 2011 4
... ... ...
10881 2012 19
10882 2012 20
10883 2012 21
10884 2012 22
10885 2012 23
[10886 rows x 2 columns]
month day
0 1 1
1 1 1
2 1 1
3 1 1
4 1 1
... ... ...
10881 12 19
10882 12 19
10883 12 19
10884 12 19
10885 12 19
[10886 rows x 2 columns]
month hour
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
... ... ...
10881 12 19
10882 12 20
10883 12 21
10884 12 22
10885 12 23
[10886 rows x 2 columns]
day hour
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
... ... ...
10881 19 19
10882 19 20
10883 19 21
10884 19 22
10885 19 23
[10886 rows x 2 columns]
In [29]:
for c in combinations(f, 2):
X_train, X_test, y_train, y_test = train_test_split(df[list(c)], df['count'], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(str(c))
print("train : ", train_score)
print("test : ", test_score)
print("="*20)
('season', 'holiday')
train : 0.05845819571136379
test : 0.06801029389571611
====================
('season', 'workingday')
train : 0.06119690546536827
test : 0.06356368452321925
====================
('season', 'weather')
train : 0.07576082202281542
test : 0.08724412927488545
====================
('season', 'temp')
train : 0.23284427316676115
test : 0.2126150527730073
====================
('season', 'humidity')
train : 0.28060963515764825
test : 0.2553308376517509
====================
('season', 'windspeed')
train : 0.09695952795617624
test : 0.0870184127764726
====================
('season', 'year')
train : 0.12481734997659888
test : 0.1419045806133954
====================
('season', 'month')
train : 0.07110487449658509
test : 0.07775741473009401
====================
('season', 'day')
train : 0.0730837414840454
test : 0.0508598813046125
====================
('season', 'hour')
train : 0.6119506571560571
test : 0.603707014633353
====================
('holiday', 'workingday')
train : 6.254614111333989e-05
test : -7.213416623663704e-05
====================
('holiday', 'weather')
train : 0.018203745414681616
test : 0.017385163764621958
====================
('holiday', 'temp')
train : 0.16992644518592026
test : 0.18105496093542683
====================
('holiday', 'humidity')
train : 0.13910601748660945
test : 0.1188547039149569
====================
('holiday', 'windspeed')
train : 0.019516032040894027
test : 0.01644872706450229
====================
('holiday', 'year')
train : 0.07140907585286749
test : 0.05987754943200241
====================
('holiday', 'month')
train : 0.07170470686238317
test : 0.07658428013922136
====================
('holiday', 'day')
train : 0.007090447830976676
test : -0.002347600544694739
====================
('holiday', 'hour')
train : 0.5203690714412798
test : 0.5147726988065502
====================
('workingday', 'weather')
train : 0.017652970990177486
test : 0.018520313691839374
====================
('workingday', 'temp')
train : 0.17701773948619048
test : 0.1656941296996629
====================
('workingday', 'humidity')
train : 0.1458885900358774
test : 0.12107148034198867
====================
('workingday', 'windspeed')
train : 0.025180747003014092
test : 0.009864892264444092
====================
('workingday', 'year')
train : 0.06463100782531617
test : 0.0758191172864463
====================
('workingday', 'month')
train : 0.07721271823416076
test : 0.0669414583433603
====================
('workingday', 'day')
train : 0.00513734237636676
test : -0.0019346627158343122
====================
('workingday', 'hour')
train : 0.6538749506801984
test : 0.6533623225870554
====================
('weather', 'temp')
train : 0.19434607518171065
test : 0.17027741524867768
====================
('weather', 'humidity')
train : 0.15828235468992424
test : 0.10505369754010518
====================
('weather', 'windspeed')
train : 0.04406413642063167
test : 0.03658864299539133
====================
('weather', 'year')
train : 0.08756829553309142
test : 0.07928282501967343
====================
('weather', 'month')
train : 0.09587192759658014
test : 0.08846831294974555
====================
('weather', 'day')
train : 0.030841733528468973
test : 0.009799462464378794
====================
('weather', 'hour')
train : 0.5532384362164128
test : 0.5332867151807875
====================
('temp', 'humidity')
train : 0.3686949135390849
test : 0.24043607129139977
====================
('temp', 'windspeed')
train : 0.2590220131987515
test : 0.11573756231088816
====================
('temp', 'year')
train : 0.23753762757820374
test : 0.21815533604779336
====================
('temp', 'month')
train : 0.2880174693849482
test : 0.22970742981217374
====================
('temp', 'day')
train : 0.2663310001326936
test : 0.14210666955745732
====================
('temp', 'hour')
train : 0.679074285859746
test : 0.6037291739012631
====================
('humidity', 'windspeed')
train : 0.25819049064192934
test : 0.036960054751834504
====================
('humidity', 'year')
train : 0.20136505635494273
test : 0.18650522639089195
====================
('humidity', 'month')
train : 0.38909825925915065
test : 0.2496396608260928
====================
('humidity', 'day')
train : 0.3194661339783871
test : 0.06093953967038068
====================
('humidity', 'hour')
train : 0.6346694753826874
test : 0.5050059135565201
====================
('windspeed', 'year')
train : 0.09323464953999572
test : 0.08183108426857966
====================
('windspeed', 'month')
train : 0.13519972851366324
test : 0.06816860927886215
====================
('windspeed', 'day')
train : 0.06735231888334947
test : -0.012116863497556363
====================
('windspeed', 'hour')
train : 0.5454843269854666
test : 0.4981731533709608
====================
('year', 'month')
train : 0.14949221759923648
test : 0.13777955850772106
====================
('year', 'day')
train : 0.06481644985431456
test : 0.07503715410081335
====================
('year', 'hour')
train : 0.6219452481465291
test : 0.6155966763154723
====================
('month', 'day')
train : 0.10347692407809816
test : 0.0417316959498103
====================
('month', 'hour')
train : 0.6344925826836026
test : 0.6095869000632028
====================
('day', 'hour')
train : 0.5278468147569957
test : 0.47347898020353973
====================
In [30]:
for c in combinations(f, 2):
X_train, X_test, y_train, y_test = train_test_split(df[list(c)], df['count'], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
result = {"combination" : str(c), "train" : train_score, "test" : test_score}
all_result.append(result)
all_result
Out[30]:
[{'combination': "('season', 'holiday')",
'train': 0.06429541388996607,
'test': 0.05439025396453023},
{'combination': "('season', 'workingday')",
'train': 0.06534159774564652,
'test': 0.05273019184958949},
{'combination': "('season', 'weather')",
'train': 0.08216391857162053,
'test': 0.07265795524806051},
{'combination': "('season', 'temp')",
'train': 0.2351771066164272,
'test': 0.20490765892966023},
{'combination': "('season', 'humidity')",
'train': 0.2856744999467695,
'test': 0.24563783000940131},
{'combination': "('season', 'windspeed')",
'train': 0.09543727422483361,
'test': 0.08810482783949436},
{'combination': "('season', 'year')",
'train': 0.13202699951491037,
'test': 0.12640899224946056},
{'combination': "('season', 'month')",
'train': 0.0741459578302236,
'test': 0.06991633720348411},
{'combination': "('season', 'day')",
'train': 0.07435037626015506,
'test': 0.04502838971546008},
{'combination': "('season', 'hour')",
'train': 0.6064060557910389,
'test': 0.6161882221308241},
{'combination': "('holiday', 'workingday')",
'train': 9.283914579183428e-05,
'test': -0.0006753884944799005},
{'combination': "('holiday', 'weather')",
'train': 0.01698704128836559,
'test': 0.020411523484866634},
{'combination': "('holiday', 'temp')",
'train': 0.17543847668694112,
'test': 0.16892160464232586},
{'combination': "('holiday', 'humidity')",
'train': 0.1519459899428811,
'test': 0.08329276861928858},
{'combination': "('holiday', 'windspeed')",
'train': 0.022829782512737373,
'test': 0.008072210959060855},
{'combination': "('holiday', 'year')",
'train': 0.07105795444215501,
'test': 0.06048052370486012},
{'combination': "('holiday', 'month')",
'train': 0.07507252836735323,
'test': 0.06951961287107877},
{'combination': "('holiday', 'day')",
'train': 0.0068259510156423175,
'test': 0.003024065717116664},
{'combination': "('holiday', 'hour')",
'train': 0.5228490974196865,
'test': 0.5080892804225323},
{'combination': "('workingday', 'weather')",
'train': 0.020828301449846043,
'test': 0.011411014014170995},
{'combination': "('workingday', 'temp')",
'train': 0.17502869489703998,
'test': 0.17364869335565458},
{'combination': "('workingday', 'humidity')",
'train': 0.14476689394463738,
'test': 0.12851029339806597},
{'combination': "('workingday', 'windspeed')",
'train': 0.023235429159391696,
'test': 0.01615716563294245},
{'combination': "('workingday', 'year')",
'train': 0.07277112893558291,
'test': 0.05661629910846899},
{'combination': "('workingday', 'month')",
'train': 0.07715409638606674,
'test': 0.06466835772871471},
{'combination': "('workingday', 'day')",
'train': 0.005231127635079602,
'test': -0.0036445773889950406},
{'combination': "('workingday', 'hour')",
'train': 0.65163346772907,
'test': 0.65980453848609},
{'combination': "('weather', 'temp')",
'train': 0.1952024653027693,
'test': 0.16654321420746143},
{'combination': "('weather', 'humidity')",
'train': 0.15658685847221743,
'test': 0.10298867496824105},
{'combination': "('weather', 'windspeed')",
'train': 0.0474964097877556,
'test': 0.02771650824026939},
{'combination': "('weather', 'year')",
'train': 0.09116637560345542,
'test': 0.07078163179731245},
{'combination': "('weather', 'month')",
'train': 0.09422581958616993,
'test': 0.09301492937102684},
{'combination': "('weather', 'day')",
'train': 0.02716329585565125,
'test': 0.019863988688087142},
{'combination': "('weather', 'hour')",
'train': 0.5558689455886267,
'test': 0.5285109716235332},
{'combination': "('temp', 'humidity')",
'train': 0.37535892235591173,
'test': 0.23880588782898804},
{'combination': "('temp', 'windspeed')",
'train': 0.25899025839398493,
'test': 0.12629183224336316},
{'combination': "('temp', 'year')",
'train': 0.2356678407766435,
'test': 0.22465200787573958},
{'combination': "('temp', 'month')",
'train': 0.28378494720565084,
'test': 0.2352749739844313},
{'combination': "('temp', 'day')",
'train': 0.2698911501769191,
'test': 0.13544182234706081},
{'combination': "('temp', 'hour')",
'train': 0.6904494294728518,
'test': 0.5739633601701017},
{'combination': "('humidity', 'windspeed')",
'train': 0.2705701220348399,
'test': 0.01345498635788167},
{'combination': "('humidity', 'year')",
'train': 0.20736843182661158,
'test': 0.17373936030535997},
{'combination': "('humidity', 'month')",
'train': 0.386774099530133,
'test': 0.2711809725326212},
{'combination': "('humidity', 'day')",
'train': 0.31456450734972696,
'test': 0.06626831878009554},
{'combination': "('humidity', 'hour')",
'train': 0.6484746860145716,
'test': 0.4599222799053242},
{'combination': "('windspeed', 'year')",
'train': 0.094354903191749,
'test': 0.0771786967680903},
{'combination': "('windspeed', 'month')",
'train': 0.13161596556156407,
'test': 0.08218792527707564},
{'combination': "('windspeed', 'day')",
'train': 0.07047871647514425,
'test': -0.018641448646160574},
{'combination': "('windspeed', 'hour')",
'train': 0.553397149647815,
'test': 0.48190568850884374},
{'combination': "('year', 'month')",
'train': 0.14710504454494133,
'test': 0.1424721899303245},
{'combination': "('year', 'day')",
'train': 0.07342932178624018,
'test': 0.05346903169933215},
{'combination': "('year', 'hour')",
'train': 0.6208178463861078,
'test': 0.6179964590935694},
{'combination': "('month', 'day')",
'train': 0.09841937927428457,
'test': 0.05207547071903362},
{'combination': "('month', 'hour')",
'train': 0.6386774092912783,
'test': 0.6014056338728897},
{'combination': "('day', 'hour')",
'train': 0.5235915799173942,
'test': 0.48925313013863636}]
In [37]:
# test 를 기준으로 오름차순으로 정렬
result_df = pd.DataFrame(all_result).sort_values(by="test")
# test 의 점수가 가장 높은 5가지를 확인
result_df.tail()
Out[37]:
| combination | train | test | |
|---|---|---|---|
| 9 | ('season', 'hour') | 0.606406 | 0.616188 |
| 51 | ('year', 'hour') | 0.620818 | 0.617996 |
| 81 | ('workingday', 'hour') | 0.657728 | 0.644720 |
| 136 | ('workingday', 'hour') | 0.657899 | 0.644887 |
| 26 | ('workingday', 'hour') | 0.651633 | 0.659805 |
In [38]:
fe = ['season', 'holiday', 'workingday', 'weather', 'temp',
'humidity', 'windspeed', 'year', 'month', 'day', 'hour']
# 가장 좋은 조합
best_f = ["workingday", "hour"]
In [41]:
all_result = []
for f in fe:
# 가장 좋은 조합을 확인하기 위해
# feature 하나씩 추가해서 확인
best_f.append(f)
# print(best_f)
X_train, X_test, y_train, y_test = train_test_split(df[best_f], df['count'], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
train_s = model.score(X_train, y_train)
test_s = model.score(X_test, y_test)
result = {"combin" : best_f.copy(), "train" : train_s, "test" : test_s}
all_result.append(result)
# 다음 feature를 넣어서 확인하기 위해 마지막에 넣은 feature 제거
best_f.pop()
# print(best_f)
all_result
Out[41]:
[{'combin': ['workingday', 'hour', 'season'],
'train': 0.7580913458160565,
'test': 0.7440944945103845},
{'combin': ['workingday', 'hour', 'holiday'],
'train': 0.6650019150696596,
'test': 0.6345567260841918},
{'combin': ['workingday', 'hour', 'workingday'],
'train': 0.6590593073097475,
'test': 0.6431016423118261},
{'combin': ['workingday', 'hour', 'weather'],
'train': 0.6926684259802643,
'test': 0.6668174416876799},
{'combin': ['workingday', 'hour', 'temp'],
'train': 0.8323620614455098,
'test': 0.7295907373392445},
{'combin': ['workingday', 'hour', 'humidity'],
'train': 0.8004993632245669,
'test': 0.600456524550598},
{'combin': ['workingday', 'hour', 'windspeed'],
'train': 0.6990780034197865,
'test': 0.6266172439536393},
{'combin': ['workingday', 'hour', 'year'],
'train': 0.767761505426242,
'test': 0.7636787124282669},
{'combin': ['workingday', 'hour', 'month'],
'train': 0.7863534443871265,
'test': 0.7419456112733107},
{'combin': ['workingday', 'hour', 'day'],
'train': 0.6762676095319997,
'test': 0.5931861225822459},
{'combin': ['workingday', 'hour', 'hour'],
'train': 0.6560251705446849,
'test': 0.6500550217881965}]
In [42]:
# test 를 기준으로 오름차순으로 정렬
result_df = pd.DataFrame(all_result).sort_values(by="test")
# test 의 점수가 가장 높은 5가지를 확인
result_df.tail()
Out[42]:
| combin | train | test | |
|---|---|---|---|
| 3 | [workingday, hour, weather] | 0.692668 | 0.666817 |
| 4 | [workingday, hour, temp] | 0.832362 | 0.729591 |
| 8 | [workingday, hour, month] | 0.786353 | 0.741946 |
| 0 | [workingday, hour, season] | 0.758091 | 0.744094 |
| 7 | [workingday, hour, year] | 0.767762 | 0.763679 |
In [50]:
# 함수로 위 과정 처리
def features_select(feature, best_f):
all_result = []
for f in feature:
# 가장 좋은 조합을 확인하기 위해
# feature 하나씩 추가해서 확인
best_f.append(f)
# print(best_f)
X_train, X_test, y_train, y_test = train_test_split(df[best_f], df['count'], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
train_s = model.score(X_train, y_train)
test_s = model.score(X_test, y_test)
result = {"combin" : best_f.copy(), "train" : train_s, "test" : test_s}
all_result.append(result)
# 다음 feature를 넣어서 확인하기 위해 마지막에 넣은 feature 제거
best_f.pop()
# print(best_f)
return all_result;
In [51]:
fe = ['season', 'holiday', 'workingday', 'weather', 'temp',
'humidity', 'windspeed', 'month', 'day', 'hour']
# 가장 좋은 조합
best_f = ["workingday", "hour", "year"]
In [52]:
# test 를 기준으로 오름차순으로 정렬
result_df = pd.DataFrame(features_select(fe, best_f)).sort_values(by="test")
# test 의 점수가 가장 높은 5가지를 확인
result_df.tail()
Out[52]:
| combin | train | test | |
|---|---|---|---|
| 2 | [workingday, hour, year, workingday] | 0.764556 | 0.771759 |
| 3 | [workingday, hour, year, weather] | 0.802760 | 0.778615 |
| 4 | [workingday, hour, year, temp] | 0.927649 | 0.848878 |
| 0 | [workingday, hour, year, season] | 0.874880 | 0.861009 |
| 7 | [workingday, hour, year, month] | 0.906467 | 0.881726 |
In [ ]:
In [ ]:
In [53]:
# 이제 후진 선택법을 사용해 볼 것임
fe = ['season', 'holiday', 'workingday', 'weather', 'temp',
'humidity', 'windspeed', 'month', 'day', 'hour', "workingday", "hour", "year"]
# best_f = []
In [55]:
all_result = []
for c in combinations(fe, len(fe)-1):
# feature 에서 전체 컬럼의 수 -1 을 해서 하나씩 빼가면서
# 테스트를 해보겠다는 뜻
target = list(c)
# print(target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
train_s = model.score(X_train, y_train)
test_s = model.score(X_test, y_test)
dropped = set(fe) - set(target)
result = {"dropped":dropped, "train":train_s, "test":test_s}
all_result.append(result)
In [57]:
result_df = pd.DataFrame(all_result).sort_values(by="test")
result_df
Out[57]:
| dropped | train | test | |
|---|---|---|---|
| 5 | {month} | 0.992111 | 0.930813 |
| 4 | {day} | 0.991652 | 0.932279 |
| 0 | {year} | 0.991575 | 0.936426 |
| 6 | {windspeed} | 0.992017 | 0.936628 |
| 1 | {} | 0.991685 | 0.937244 |
| 8 | {temp} | 0.991496 | 0.937614 |
| 11 | {holiday} | 0.991583 | 0.939131 |
| 10 | {} | 0.991901 | 0.939687 |
| 12 | {season} | 0.991995 | 0.940164 |
| 9 | {weather} | 0.991278 | 0.941420 |
| 3 | {} | 0.991178 | 0.942275 |
| 7 | {humidity} | 0.991742 | 0.943053 |
| 2 | {} | 0.991287 | 0.944364 |
In [ ]:
In [ ]:
In [58]:
fe = ['season', 'holiday', 'workingday', 'weather', 'temp',
'humidity', 'windspeed', 'month', 'day', 'hour', "workingday", "hour", "year"]
In [60]:
from sklearn.feature_selection import RFE
model = RandomForestRegressor()
rfe = RFE( estimator = model )
rfe.fit(X_train, y_train)
rfe_df = pd.DataFrame()
rfe_df["ranking"] = rfe.ranking_
rfe_df["features"] = X_train.columns
rfe_df
Out[60]:
| ranking | features | |
|---|---|---|
| 0 | 5 | season |
| 1 | 7 | holiday |
| 2 | 1 | workingday |
| 3 | 4 | weather |
| 4 | 1 | temp |
| 5 | 2 | atemp |
| 6 | 1 | humidity |
| 7 | 6 | windspeed |
| 8 | 1 | year |
| 9 | 1 | month |
| 10 | 3 | day |
| 11 | 1 | hour |
In [62]:
# ranking 이 높을수록 결과 값에 영향을 크게 미치는
# 중요한 컬럼들
rfe_df.sort_values(by="ranking")
Out[62]:
| ranking | features | |
|---|---|---|
| 2 | 1 | workingday |
| 4 | 1 | temp |
| 6 | 1 | humidity |
| 8 | 1 | year |
| 9 | 1 | month |
| 11 | 1 | hour |
| 5 | 2 | atemp |
| 10 | 3 | day |
| 3 | 4 | weather |
| 0 | 5 | season |
| 7 | 6 | windspeed |
| 1 | 7 | holiday |
In [68]:
feature = ['workingday', 'temp', 'humidity', 'year', 'month', 'hour', 'atemp']
In [69]:
model = RandomForestRegressor()
model.fit(X_train, y_train)
print("train : ", model.score(X_train, y_train))
print("test : ", model.score(X_test, y_test))
# 모든 컬럼을 사용했을때 평가점수
train : 0.9918053687355339 test : 0.9402065652970045
In [70]:
X_train.columns
Out[70]:
Index(['season', 'holiday', 'workingday', 'weather', 'temp', 'atemp',
'humidity', 'windspeed', 'year', 'month', 'day', 'hour'],
dtype='object')
In [72]:
X_tr, X_te, y_tr, y_te = train_test_split(df[feature], df[l], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_tr, y_tr)
print("train : ", model.score(X_tr, y_tr))
print("test : ", model.score(X_te, y_te))
# 결과에 영향을 크게 주는 컬럼들을 사용했을때 평가 점수
train : 0.9895003195998577 test : 0.9279685991163032
In [ ]:
In [ ]:
In [74]:
# embed 방식 변수 선택법을 확인해볼 것임
model = RandomForestRegressor()
model.fit(X_train, y_train)
print("train : ", model.score(X_train, y_train))
print("test : ", model.score(X_test, y_test))
print(model.feature_importances_)
print(X_train.columns)
train : 0.9917659298573632
test : 0.9393860178830495
[0.01127486 0.00352902 0.07385774 0.01356585 0.09019879 0.02357791
0.02972932 0.00938863 0.08657932 0.03626527 0.01343145 0.60860183]
Index(['season', 'holiday', 'workingday', 'weather', 'temp', 'atemp',
'humidity', 'windspeed', 'year', 'month', 'day', 'hour'],
dtype='object')
In [77]:
df_1 = pd.DataFrame()
# feature_importances 는 Tree 계열 알고리즘에서만 존재한다
# 이 방법이 embed 방법!!
df_1['rank'] = model.feature_importances_
df_1['feature'] = X_train.columns
df_1.sort_values(by="rank", ascending=False)
Out[77]:
| rank | feature | |
|---|---|---|
| 0 | 0.617593 | hour |
| 1 | 0.122718 | temp |
| 2 | 0.082577 | year |
| 3 | 0.071475 | workingday |
| 4 | 0.055804 | month |
| 5 | 0.049833 | humidity |
In [78]:
f = ['hour', 'temp', 'year', 'workingday', 'month', 'humidity']
X_train, X_test, y_train, y_test = train_test_split(df[f], df[l], test_size=0.3)
model = RandomForestRegressor()
model.fit(X_train, y_train)
print("train : ", model.score(X_train, y_train))
print("test : ", model.score(X_test, y_test))
train : 0.9889267902576386 test : 0.9297102519637512
728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 군집 ( 고객분류 ) (0) | 2024.05.28 |
|---|---|
| [머신러닝] 회귀 및 평가지표 (0) | 2024.05.27 |
| [머신러닝] 과적합 및 하이퍼파라미터 (0) | 2024.05.27 |
| [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 (0) | 2024.05.24 |
| [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) (0) | 2024.05.24 |
[머신러닝] 회귀 및 평가지표
2024. 5. 27. 14:33
회귀 및 평가지표
회귀 및 평가지표.pdf
4.60MB
회귀 및 평가지표.ipynb
0.42MB
회귀 및 평가지표.html
0.70MB
사진이 포함되어 있으므로 pdf 로 확인
회귀¶
- 독립변수가 종속변수에 영향을 미치는지 알아보고자 할 때 사용
- 연속형 변수들에 대해 두 변수 사이의 적합도를 측정
- 단순회귀
- 하나의 종속변수와 하나의 독립변수 사이의 관계 분석
- 다중회귀
- 하나의 종속변수와 여러 독립변수 사이의 관계 분석

In [ ]:
# 회귀란? 최적의 선을 찾는것...!!!
# 최적의 선이랑 예측 값의 선....
# 예측 값의 선으로 부터 결과 값들의 거리가 작을수록 좋은 예측이다
회귀 평가지표¶
- MSE(Mean Squared Error)(평균 제곱 오차)
- 예측값과 실제값의 차이에 대한 제곱에 대하여 평균을 낸 값
- 회귀 문제에서 가장 많이 사용하는 성능 지표
- 모델을 평가하는 평가 지표로 오차를 나타내는 식이므로 수치가 적을 수록 좋은 모델
- 다른 모델과 비교해야만 성능이 좋은지 알 수 있다.
- RMSE(Root Mean Squared Error)
- 0에 가까울수록 좋은 모델
- MSE에 ROOT를 쒸운 값
- MAE(Mean Absolute Error, 평균 절대 오차)
- 실제값 대비 예측값의 오차를 나타내는 것으로 값이 낮을 수록 좋다
- 예측값과 실제값의 차이에 대한 절대값에 대하여 평균을 낸 값
- MAPE(Mean Absolute Percentage Error, 평균 절대 비율 오차)
- 실제값 대비 예측차이가 얼마나 있는지를 비율(%)로 측정
- 퍼센트값을 가지며 0에 가까울수록 회귀모형의 성능이 좋다고 해석
- r2(결정계수)
- 0~1 사이의 값을 표현해 주며 r2의 값이 높을수록 좋다
- 예측 모델과 실제 모델이 얼마나 강한 상관관계를 가지고 있는지
- 타겟 데이터
- 1978년 보스턴 주택 가격
- 506개 타운의 주택 가격 중앙값(단위 1,000달러)
- 특징 데이터
- CRIM : 범죄율
- ZM : 25,000평방 피트 당 주거용 토지의 비율
- INDUS : 비소매상업지역 면적 비율
- CHAS : 찰스강의 경계에 위치한 경우는 1, 아니면 0(통로가 하천을 향하면1, 아니면 0)
- NOX : 일산화질소 농도(천만분의 1)
- RM : 주택당 방수
- AGE : 1940년 이전에 건축된 주택의 비율
- DIS : 5개 주요 고용센터까지의 가중거리
- RAD : 고속도로 접근성 지수
- TAX : 재산세율
- PTRATIO : 학생/교사 비율
- B ; 인구 중 흑인 거주 비율
- LSTAT : 인구 중 하위 계층 비율
- MEDV : 본인 소유의 주택가격(중앙값) (단위: $1,000)
In [1]:
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
In [2]:
df = pd.read_csv("../data_set/6.회귀/HousingData.csv")
df.head()
Out[2]:
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 0.00 | 36.2 |
In [3]:
from sklearn.model_selection import train_test_split
y = df['MEDV']
X = df.drop(["MEDV"], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
In [4]:
from sklearn.neighbors import KNeighborsRegressor
kn = KNeighborsRegressor()
kn.fit(X_train, y_train)
Out[4]:
KNeighborsRegressor()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsRegressor()
In [20]:
pred = kn.predict( X_test )
pred
Out[20]:
array([23.46, 15.06, 23.38, 25.44, 22.14, 16.52, 20.02, 28.02, 23.52,
21.5 , 41.54, 16.52, 23.9 , 29.94, 23.56, 17.32, 21.46, 24.3 ,
14.84, 28.64, 23.46, 24.78, 17.92, 29.26, 18.62, 20.6 , 20.56,
20.64, 18.32, 15.54, 11.68, 18.32, 28.72, 39.32, 38. , 20.16,
27.36, 20.98, 23.94, 24.06, 30.38, 9.96, 16.64, 34.9 , 28.76,
15.4 , 30.02, 23.82, 13.26, 10.56, 28.02, 33.18, 20.88, 22.62,
28.36, 24.56, 23.16, 21.64, 26.14, 11.14, 28.06, 15.2 , 21.5 ,
13.26, 12.88, 13.34, 25.38, 12.3 , 13.28, 26.44, 23.96, 28.22,
31.48, 18.24, 15.4 , 28.42, 24.46, 23.9 , 21.72, 34.34, 16.84,
8.2 , 28.02, 23.36, 20.7 , 32.32, 12.34, 28.26, 15.4 , 29. ,
20.9 , 29.86, 23. , 21.5 , 21.5 , 22.08, 20.96, 20.76, 28.06,
13.1 , 17.96, 19.58, 14.76, 18.62, 11.92, 11.46, 18.14, 36.86,
29.04, 22.48, 29.82, 25.52, 24.82, 14.68, 29.96, 28.02, 21.12,
10.8 , 22.68, 20.7 , 30.34, 10.04, 21.64, 41.54, 12.32, 21.58,
19.94, 31.92, 22.12, 11.82, 24.78, 19.26, 25.38, 36.18, 29.66,
16.74, 22.38, 20.12, 41.54, 11.94, 22.42, 12.18, 17.76, 25.48,
17.58, 27.02, 22.48, 24.66, 35.24, 27.82, 22.68, 40.16])
In [6]:
y_test
Out[6]:
63 25.0
417 10.4
339 19.0
84 23.9
215 25.0
...
294 21.7
232 41.7
150 21.5
172 23.1
94 20.6
Name: MEDV, Length: 152, dtype: float64
In [21]:
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y_test, pred)
r2 = r2_score(y_test, pred)
print("mse : ", mse)
print("r2 : ", r2)
print("score : ", kn.score(X_train, y_train))
print("score : ", kn.score(X_test, y_test))
# mse 는 0과 가까울 수록 좋은 결과
# r2, score 는 높을 수록 좋은 결과
mse : 43.82906578947368 r2 : 0.5349249633916936 score : 0.6057676219071229 score : 0.5349249633916936
In [ ]:
In [ ]:
In [17]:
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.fit(X_train, y_train)
Out[17]:
RandomForestRegressor()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestRegressor()
In [19]:
pred = rfr.predict( X_test )
mse = mean_squared_error(y_test, pred)
r2 = r2_score(y_test, pred)
print("mse : ", mse)
print("r2 : ", r2)
print("score : ", rfr.score(X_train, y_train))
print("score : ", rfr.score(X_test, y_test))
mse : 13.420632730263165 r2 : 0.857592190344317 score : 0.9701950979154201 score : 0.857592190344317
In [ ]:
In [ ]:
자전거 수요 예측¶
- 자전거 수요를 파악하여 효율적으로 자전거 대여수를 예측하고자 한다
- 월, 일, 시 별로 언제 자전거를 많이 대여하는지를 파악한다
- 컬럼
- datetime : 대여 날짜
- season : 1(봄), 2(여름), 3(가을), 4(겨울)
- holiday : 1(토,일 주말을 제외한 국경일 등의 휴일), 0(휴일이 아닌 날)
- workingday : 1(토, 일 주말 및 휴일이 아닌 주중), 0(주말 및 휴일)
- weather : 1(맑음), 2(흐림), 3(가벼운 눈, 비), 4(심한 눈, 비)
- temp : 온도(섭씨)
- atemp : 체감온도(섭씨)
- humidity : 습도
- windspeed : 풍속
- casual : 비등록 대여 횟수
- registered : 등록 대여 횟수
- count : 총 대여 횟수
In [23]:
df = pd.read_csv("../data_set/6.회귀/data.csv")
df.head()
Out[23]:
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 |
In [24]:
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10886 entries, 0 to 10885 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 datetime 10886 non-null object 1 season 10886 non-null int64 2 holiday 10886 non-null int64 3 workingday 10886 non-null int64 4 weather 10886 non-null int64 5 temp 10886 non-null float64 6 atemp 10886 non-null float64 7 humidity 10886 non-null int64 8 windspeed 10886 non-null float64 9 casual 10886 non-null int64 10 registered 10886 non-null int64 11 count 10886 non-null int64 dtypes: float64(3), int64(8), object(1) memory usage: 1020.7+ KB
In [25]:
# 문자열(object) 형식으로 저장되어 있던 datetime 을
# datetime 자료형으로 변환
df['datetime'] = df['datetime'].apply(pd.to_datetime)
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10886 entries, 0 to 10885 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 datetime 10886 non-null datetime64[ns] 1 season 10886 non-null int64 2 holiday 10886 non-null int64 3 workingday 10886 non-null int64 4 weather 10886 non-null int64 5 temp 10886 non-null float64 6 atemp 10886 non-null float64 7 humidity 10886 non-null int64 8 windspeed 10886 non-null float64 9 casual 10886 non-null int64 10 registered 10886 non-null int64 11 count 10886 non-null int64 dtypes: datetime64[ns](1), float64(3), int64(8) memory usage: 1020.7 KB
In [29]:
# 년 / 월 / 일 / 시
# 컬럼으로 따로 분리
df['year'] = df['datetime'].dt.year
df['month'] = df['datetime'].dt.month
df['day'] = df['datetime'].dt.day
df['hour'] = df['datetime'].dt.hour
In [28]:
df.head()
Out[28]:
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | day | hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011 | 1 | 1 | 0 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011 | 1 | 1 | 1 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011 | 1 | 1 | 2 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011 | 1 | 1 | 3 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011 | 1 | 1 | 4 |
In [31]:
# 시간 별로 빌린 자전거 댓수의 합
d = df.groupby('hour').agg({"count":sum}).reset_index()
d
Out[31]:
| hour | count | |
|---|---|---|
| 0 | 0 | 25088 |
| 1 | 1 | 15372 |
| 2 | 2 | 10259 |
| 3 | 3 | 5091 |
| 4 | 4 | 2832 |
| 5 | 5 | 8935 |
| 6 | 6 | 34698 |
| 7 | 7 | 96968 |
| 8 | 8 | 165060 |
| 9 | 9 | 100910 |
| 10 | 10 | 79667 |
| 11 | 11 | 95857 |
| 12 | 12 | 116968 |
| 13 | 13 | 117551 |
| 14 | 14 | 111010 |
| 15 | 15 | 115960 |
| 16 | 16 | 144266 |
| 17 | 17 | 213757 |
| 18 | 18 | 196472 |
| 19 | 19 | 143767 |
| 20 | 20 | 104204 |
| 21 | 21 | 79057 |
| 22 | 22 | 60911 |
| 23 | 23 | 40816 |
In [35]:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(7,5))
sns_result = sns.pointplot(data=d, x="hour", y="count")
plt.xticks(rotation=45)
plt.title("bicycle rental", fontsize=15, color="black")
plt.show()

In [44]:
# 휴일과 휴일이 아닌 날로 그룹화
d = df.groupby(['hour','workingday']).agg({"count":sum}).reset_index()
d.head()
Out[44]:
| hour | workingday | count | |
|---|---|---|---|
| 0 | 0 | 0 | 13701 |
| 1 | 0 | 1 | 11387 |
| 2 | 1 | 0 | 10427 |
| 3 | 1 | 1 | 4945 |
| 4 | 2 | 0 | 7686 |
In [45]:
# 1 : 주중
# 0 : 휴일 ( 토, 일 )
sns.pointplot(data=d, x="hour", y="count", hue="workingday")
plt.show()

In [46]:
# 시간대 별, 월 별로 확인
d = df.groupby(['hour','month']).agg({"count":sum}).reset_index()
d.head()
Out[46]:
| hour | month | count | |
|---|---|---|---|
| 0 | 0 | 1 | 852 |
| 1 | 0 | 2 | 1096 |
| 2 | 0 | 3 | 1249 |
| 3 | 0 | 4 | 1480 |
| 4 | 0 | 5 | 2441 |
In [47]:
sns.pointplot(data=d, x="hour", y="count", hue="month")
plt.show()

In [49]:
# 시간대 별, 날씨 별로 확인
# weather : 1(맑음), 2(흐림), 3(가벼운 눈, 비), 4(심한 눈, 비)
d = df.groupby(['hour','weather']).agg({"count":sum}).reset_index()
d.head()
sns.pointplot(data=d, x="hour", y="count", hue="weather")
plt.show()

In [50]:
df.columns
Out[50]:
Index(['datetime', 'season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count',
'year', 'month', 'day', 'hour'],
dtype='object')
In [51]:
f = ['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'year', 'month', 'day', 'hour']
l = 'count'
X, y = df[f], df[l]
In [52]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
In [53]:
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.fit(X_train, y_train)
print("train : ", rfr.score(X_train, y_train))
print("test : ", rfr.score(X_test, y_test))
train : 0.9914114957469251 test : 0.9376778114053523
In [54]:
from sklearn.model_selection import GridSearchCV
params = {
"n_estimators" : range(5, 100, 10), # 트리 갯수(알고리즘)
"max_depth" : range(4, 11, 2), # 트리의 최대 깊이
"min_samples_split" : range(4, 21, 4) # 립노드 조건 샘플 수
}
rfr = RandomForestRegressor()
grid_cv = GridSearchCV(rfr, param_grid=params, cv=3, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print("최적의 파라미터 : ", grid_cv.best_params_)
print("train : ", grid_cv.score(X_train, y_train))
print("test : ", grid_cv.score(X_test, y_test))
최적의 파라미터 : {'max_depth': 10, 'min_samples_split': 4, 'n_estimators': 75}
train : 0.9525772588841167
test : 0.9206851922918676
In [55]:
X.head(3)
Out[55]:
| season | holiday | workingday | weather | temp | atemp | humidity | windspeed | year | month | day | hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 2011 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 2011 | 1 | 1 | 1 |
| 2 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 2011 | 1 | 1 | 2 |
In [59]:
# 대략 아래와 같은 상황에서는 자전거가 20대가 필요하겠다....!!
# 아래와 같은 계절, 흄, 날씨, 온도 등등등.... 에서
re = grid_cv.predict([[1, 0, 0, 1, 9.84, 14.395, 81, 0.0, 2011, 1, 1, 0]])
re[0]
Out[59]:
20.63599993470582
In [58]:
int(re[0])
Out[58]:
20
In [ ]:
In [ ]:
In [60]:
# 예제 : 두 값을 비교하기 위함
df_result = pd.DataFrame({"y_test ": [11,12,13,14,15,16,17,18,19],
"line_test" : [10,11,12,13,14,15,16,17,18]})
sns.lineplot(data = df_result)
plt.legend(labels=["Legend_Day1","Legend_Day2"])
# 실제 정답과 예측 정답 두가지를 넣고 lineplot를 이용하여 그리면 된다
Out[60]:
<matplotlib.legend.Legend at 0x1b203e646d0>

In [61]:
grid_cv.predict(X_test)
Out[61]:
array([147.88696059, 272.60793329, 18.18288773, ..., 197.27226131,
415.09046011, 419.37438723])
In [62]:
y_test
Out[62]:
7971 95
848 162
642 37
1023 1
6050 508
...
5327 31
3742 121
4530 209
4375 209
8311 294
Name: count, Length: 3266, dtype: int64
In [69]:
range_start = 0
range_end = 30
line_test = grid_cv.predict(X_test)
y_test_reset = y_test[range_start : range_end].reset_index()
y_test_reset['pred_test'] = line_test[range_start : range_end]
y_test_reset['pred_test'] = y_test_reset['pred_test'].apply( int )
sns.lineplot( data = y_test_reset[['count', 'pred_test']])
plt.legend(labels = ['y_test', 'pred test'])
Out[69]:
<matplotlib.legend.Legend at 0x1b20aae5b10>

728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 군집 ( 고객분류 ) (0) | 2024.05.28 |
|---|---|
| [머신러닝] 변수 선택법 ( feature selection ) (0) | 2024.05.28 |
| [머신러닝] 과적합 및 하이퍼파라미터 (0) | 2024.05.27 |
| [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 (0) | 2024.05.24 |
| [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) (0) | 2024.05.24 |
[머신러닝] 과적합 및 하이퍼파라미터
2024. 5. 27. 13:12
과적합 및 하이퍼파라미터
1. 과적합 및 스케일링
과적합 : 과적합 또는 과대적합은 기계 학습에서 학습 데이터를 과하게 학습하는 것을 뜻한다. 일반적으로 학습 데이터는 실제 데이터의 부분 집합이므로 학습 데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
1.과적합 및 스케일링.pdf
2.85MB
1.과적합 및 스케일링.html
0.37MB
1.과적합 및 스케일링.ipynb
0.08MB
2. 하이퍼 파라미터
하이퍼 파라미터 : 하이퍼 파라미터는 최적의 훈련 모델을 구현하기 위해 모델에 설정하는 변수로 학습률 ( Leraning Rate ), 에포크 수 ( 훈련 반복 횟수 ), 가중치 초기화 등을 결정할 수 있다. 이러한 하이퍼 파라미터 튜닝 기법을 적용하면 훈련 모델의 최적의 값들을 찾을 수 있다.
2.하이퍼 파라미터.pdf
3.47MB
2.하이퍼 파라미터.html
0.34MB
2.하이퍼 파라미터.ipynb
0.05MB
이미지가 포함되어 있으므로 pdf 로 확인할 것
과적합 및 스케일링



스케일링¶
- 수치형 데이터들의 값의 범위가 클 경우 사용한다.(연산 속도 증가)
- 예를 들어 주식의 가격을 생각했을 경우 100원의 1%와 100000원의 1%를 계산하고자 한다면 같은 1%연산이지만 숫자가 클 경우 연산속도에 영향을 미치게 된다.
- 서로 다른 변수의 값 범위를 일정한 수준으로 맞추고자 하는 경우
- 대표적 스케일링 클래스는 StandardScaler, MinMaxScaler이 있다
- 사용 이유
- 연산속도를 올릴 수 있다
- 확률을 높일 수 있다
- 과대, 과소적합을 조금은 해결할 수 있다
- 참고
- 이상치가 있을 경우 범위의 차이가 커지게 되므로 이상치는 제거해야 한다
- RandomForest는 따로 스케일링 할 필요가 없다.(tree계열은 따로 스케일 할 필요가 없다)

In [3]:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 가상의 영화 평점 데이터
movie = {'daum':[2,4,6,8,10], 'naver':[1,2,3,4,5]}
mv = pd.DataFrame(movie)
mv
Out[3]:
| daum | naver | |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 4 | 2 |
| 2 | 6 | 3 |
| 3 | 8 | 4 |
| 4 | 10 | 5 |
In [13]:
# standardscaler 를 사용해서
# 두 데이터 간의 범위를 줄인다
st = StandardScaler()
scaled = st.fit_transform(mv)
mv = pd.DataFrame(data = scaled, columns=['daum', 'naver'])
mv
Out[13]:
| daum | naver | |
|---|---|---|
| 0 | -1.414214e+00 | -1.414214e+00 |
| 1 | -7.071068e-01 | -7.071068e-01 |
| 2 | 4.440892e-17 | 4.440892e-17 |
| 3 | 7.071068e-01 | 7.071068e-01 |
| 4 | 1.414214e+00 | 1.414214e+00 |
In [12]:
# round() : 소숫점 범위를 잘라준다
round(scaled.std(), 2)
Out[12]:
1.0
In [ ]:
In [ ]:
In [16]:
from sklearn.preprocessing import MinMaxScaler
mv = pd.DataFrame(movie)
mv
Out[16]:
| daum | naver | |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 4 | 2 |
| 2 | 6 | 3 |
| 3 | 8 | 4 |
| 4 | 10 | 5 |
In [18]:
# MinMaxScaler 를 사용해
# 다른 두 값을 0 ~ 1 사이의 값으로
# 바꿔준다
m = MinMaxScaler()
min_max_mv = m.fit_transform(mv)
pd.DataFrame(min_max_mv, columns=['d', 'b'])
Out[18]:
| d | b | |
|---|---|---|
| 0 | 0.00 | 0.00 |
| 1 | 0.25 | 0.25 |
| 2 | 0.50 | 0.50 |
| 3 | 0.75 | 0.75 |
| 4 | 1.00 | 1.00 |
In [ ]:
In [ ]:
In [19]:
df = pd.read_csv("../data_set/5.스케일링/bank_train_clean.csv")
df.head()
Out[19]:
| age | duration | campaign | pdays | previous | y | |
|---|---|---|---|---|---|---|
| 0 | 58 | 261 | 1 | -1 | 0 | 0 |
| 1 | 44 | 151 | 1 | -1 | 0 | 0 |
| 2 | 33 | 76 | 1 | -1 | 0 | 0 |
| 3 | 47 | 92 | 1 | -1 | 0 | 0 |
| 4 | 33 | 198 | 1 | -1 | 0 | 0 |
In [20]:
df.columns
Out[20]:
Index(['age', 'duration', 'campaign', 'pdays', 'previous', 'y'], dtype='object')
In [21]:
features = ['age', 'duration', 'campaign', 'pdays', 'previous']
label = 'y'
X, y = df[features], df[label]
In [22]:
from sklearn.model_selection import train_test_split
# 학습용 70%, 테스트용 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
In [26]:
from sklearn.ensemble import RandomForestClassifier
# 머신 생성
rfc = RandomForestClassifier()
# 머신 학습
rfc.fit(X_train, y_train);
print( "학습 데이터 : ", rfc.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", rfc.score(X_test, y_test) )
# 학습 데이터의 결과와 테스트 결과의 차이가 커지면
# 과적합 되었다라고 말한다
학습 데이터 : 0.9923847442095617 test 데이터 : 0.8815246240047184
In [ ]:
In [ ]:
In [28]:
from sklearn.neighbors import KNeighborsClassifier
# 머신 생성
kn = KNeighborsClassifier()
# 머신 학습
kn.fit(X_train, y_train)
print( "학습 데이터 : ", kn.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", kn.score(X_test, y_test) )
# 학습 데이터와 test 데이터 테스트 결과의
# 차이 폭이 적으므로 좋은 알고리즘이다....
학습 데이터 : 0.9139570891395709 test 데이터 : 0.8846210557357712
In [ ]:
In [ ]:
In [30]:
# 데이터 스케일링
sc = StandardScaler()
sc.fit( X )
X2 = sc.transform( X )
X2
Out[30]:
array([[ 1.60696496, 0.0110161 , -0.56935064, -0.41145311, -0.25194037],
[ 0.28852927, -0.41612696, -0.56935064, -0.41145311, -0.25194037],
[-0.74738448, -0.70736086, -0.56935064, -0.41145311, -0.25194037],
...,
[ 2.92540065, 3.37379688, 0.72181052, 1.43618859, 1.05047333],
[ 1.51279098, 0.97014641, 0.39902023, -0.41145311, -0.25194037],
[-0.37068857, 0.39932797, -0.24656035, 1.4761376 , 4.52357654]])
In [31]:
X_train, X_test, y_train, y_test = train_test_split(X2, y, test_size=0.3)
In [35]:
# 머신 생성
rfc = RandomForestClassifier()
# 머신 학습
rfc.fit(X_train, y_train);
print( "학습 데이터 : ", rfc.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", rfc.score(X_test, y_test) )
# 스케일링된 데이터로 다시 테스트
학습 데이터 : 0.9919423642051379 test 데이터 : 0.8757003833677381
In [36]:
# 머신 생성
kn = KNeighborsClassifier()
# 머신 학습
kn.fit(X_train, y_train)
print( "학습 데이터 : ", kn.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", kn.score(X_test, y_test) )
# 스케일링된 데이터로 다시 테스트
학습 데이터 : 0.9128195405567668 test 데이터 : 0.8824830433500442
스케일링을 사용하면 과적합을 줄여줄 수도 있다¶
In [ ]:
In [ ]:
In [41]:
# fit_transform() 을 사용하여 스케일링
X2 = m.fit_transform( X )
X2
Out[41]:
array([[0.51948052, 0.05307035, 0. , 0. , 0. ],
[0.33766234, 0.03070354, 0. , 0. , 0. ],
[0.19480519, 0.01545344, 0. , 0. , 0. ],
...,
[0.7012987 , 0.22915819, 0.06451613, 0.21215596, 0.01090909],
[0.50649351, 0.10329402, 0.0483871 , 0. , 0. ],
[0.24675325, 0.07340382, 0.01612903, 0.21674312, 0.04 ]])
In [38]:
X_train, X_test, y_train, y_test = train_test_split(X2, y, test_size=0.3)
In [39]:
# 머신 생성
rfc = RandomForestClassifier()
# 머신 학습
rfc.fit(X_train, y_train);
print( "학습 데이터 : ", rfc.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", rfc.score(X_test, y_test) )
# 스케일링된 데이터로 다시 테스트
학습 데이터 : 0.9916895756311814 test 데이터 : 0.8786493659687408
In [40]:
# 머신 생성
kn = KNeighborsClassifier()
# 머신 학습
kn.fit(X_train, y_train)
print( "학습 데이터 : ", kn.score(X_train, y_train) )
# 학습된 머신 테스트 결과
print( "test 데이터 : ", kn.score(X_test, y_test) )
# 스케일링된 데이터로 다시 테스트
학습 데이터 : 0.9158846020159889 test 데이터 : 0.8817457976997936
In [ ]:
In [ ]:
In [43]:
# corr() : 데이터 간의 상관관계를 확인
df.corr()
Out[43]:
| age | duration | campaign | pdays | previous | y | |
|---|---|---|---|---|---|---|
| age | 1.000000 | -0.004648 | 0.004760 | -0.023758 | 0.001288 | 0.025155 |
| duration | -0.004648 | 1.000000 | -0.084570 | -0.001565 | 0.001203 | 0.394521 |
| campaign | 0.004760 | -0.084570 | 1.000000 | -0.088628 | -0.032855 | -0.073172 |
| pdays | -0.023758 | -0.001565 | -0.088628 | 1.000000 | 0.454820 | 0.103621 |
| previous | 0.001288 | 0.001203 | -0.032855 | 0.454820 | 1.000000 | 0.093236 |
| y | 0.025155 | 0.394521 | -0.073172 | 0.103621 | 0.093236 | 1.000000 |
In [45]:
import seaborn as sns
# annot = True : 상관관계 숫자를 출력
sns.heatmap( df.corr(), annot=True )
Out[45]:
<Axes: >

In [55]:
# features = ['age', 'duration', 'campaign', 'pdays', 'previous']
# features = ['age', 'duration', 'campaign', 'previous']
# features = ['age', 'campaign', 'previous']
features = ['age', 'campaign', 'previous']
label = 'y'
X, y = df[features], df[label]
sc = StandardScaler()
sc.fit( X )
X_scaler = sc.transform( X )
X_train, X_test, y_train, y_test = train_test_split(X_scaler, y, test_size=0.3)
In [56]:
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train);
print( "학습 데이터 : ", rfc.score(X_train, y_train) )
print( "test 데이터 : ", rfc.score(X_test, y_test) )
kn = KNeighborsClassifier()
kn.fit(X_train, y_train)
print( "학습 데이터 : ", kn.score(X_train, y_train) )
print( "test 데이터 : ", kn.score(X_test, y_test) )
학습 데이터 : 0.8956615160994723 test 데이터 : 0.8768799764081392 학습 데이터 : 0.8799886245141719 test 데이터 : 0.8695812444706577
하이퍼 파라미터
하이퍼파라미터¶
- 예측력을 높이기 위해 사용
- 과대/과소 적합을 방지하기 위해 사용
- 사용자가 지정하는 파라미터
하이퍼파라미터 튜닝¶
- 특정 알고리즘의 매개변수 값을 변경하면서 최적의 파라미터를 찾는 방식
- GridSearchCV클래스를 통해 하이퍼파라미터 탐색과 교차 검증을 한번에 수행
GridSearchCV¶
- 교차 검증으로 하이퍼파라미터 탐색을 수행한다
- 최상의 모델을 찾은 후 훈련 세트 전체를 사용해 최종 모델을 훈련한다
- 매개변수
- GridSearchCV(모델, param_grid = 파라미터, cv=반복횟수, n_jobs=코어 수(-1, 모든 코어 사용))
In [2]:
# 교차 검증이란?
# : 70 퍼센트의 학습용 데이터를 다시 쪼개서 학습하고 쪼개서 학습한 단위를
# : 단위 학습이 끝날 때마다 테스트를 진행
K-최근접 이웃 알고리즘¶
- 주위에서 가장 가까운 다른 데이터를 보고 현재 데이터를 판단
하이퍼파라미터¶
- n_neighbors
- 기본 가까운 5개의 데이터를 보고 자기 자신이 어디에 속하는지를 판단
- 비교하고자 하는 데이터의 수가 적을 수록 과대 적합이 된다
- metric : 거리계산 척도
- euclidean(녹색) : 유클리디안 거리 측정
- 목표 지점까지 가장 짧은 거리
- manhattan(빨간색) : 맨하튼 거리 측정 방법
- 찾아가는 경로의 모든 길이의 합
- euclidean(녹색) : 유클리디안 거리 측정
- weights : 가중치
- uniform : 거리에 가중치 부여하지 않음(균일한 가중치)
- distance : 거리에 가중치 부여(가까이 있는 데이터에 가중치)

In [ ]:
In [ ]:
In [3]:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
In [4]:
df = pd.read_csv("../data_set/5.스케일링/titanic_cleaning.csv")
df.head()
Out[4]:
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 |
| 1 | 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 |
| 2 | 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 |
| 3 | 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 |
| 4 | 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 |
In [6]:
df.columns
Out[6]:
Index(['PassengerId', 'Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch',
'Fare'],
dtype='object')
In [19]:
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']
label = "Survived"
X, y = df[features], df[label]
In [20]:
minMaxScaler = MinMaxScaler()
minMaxScaler.fit(X)
X_scaler = minMaxScaler.transform(X)
In [21]:
# 학습용 80%, 테스트용 20%
X_train_minMax, X_test_minMax, y_train, y_test = train_test_split(X_scaler, y, test_size=0.2)
In [22]:
# 알고리즘 생성
knn = KNeighborsClassifier()
knn.fit(X_train_minMax, y_train)
print("train ", knn.score(X_train_minMax, y_train))
print("test ", knn.score(X_test_minMax, y_test))
train 0.8721910112359551 test 0.8212290502793296
In [25]:
k_param = range(1, 11)
train_list = []
test_list = []
for k in k_param:
knn = KNeighborsClassifier( n_neighbors=k )
knn.fit(X_train_minMax, y_train)
# print("k : ", k, "train : ", knn.score(X_train_minMax, y_train), knn.score(X_test_minMax, y_test))
train_list.append(knn.score(X_train_minMax, y_train))
test_list.append(knn.score(X_test_minMax, y_test))
dic = {
"k" : k_param,
"train 정확도" : train_list,
"test 정확도" : test_list
}
score_df = pd.DataFrame(dic)
score_df
Out[25]:
| k | train 정확도 | test 정확도 | |
|---|---|---|---|
| 0 | 1 | 0.985955 | 0.754190 |
| 1 | 2 | 0.896067 | 0.793296 |
| 2 | 3 | 0.887640 | 0.810056 |
| 3 | 4 | 0.863764 | 0.826816 |
| 4 | 5 | 0.872191 | 0.821229 |
| 5 | 6 | 0.855337 | 0.826816 |
| 6 | 7 | 0.851124 | 0.804469 |
| 7 | 8 | 0.838483 | 0.821229 |
| 8 | 9 | 0.839888 | 0.787709 |
| 9 | 10 | 0.841292 | 0.787709 |
In [29]:
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc("font", family = "Malgun Gothic")
fig, ax = plt.subplots( figsize = (5,5) )
sns.lineplot( x="k", y="train 정확도", data=score_df )
sns.lineplot( x="k", y="test 정확도", data=score_df )
Out[29]:
<Axes: xlabel='k', ylabel='train 정확도'>

In [32]:
from sklearn.model_selection import GridSearchCV
# params = {
# "n_neighbors" : k_param
# }
params = {
"n_neighbors" : range(1, 11),
"metric" : ["manhattan", "euclidean"],
"weights" : ["uniform", "distance"]
}
knn = KNeighborsClassifier()
grid_cv = GridSearchCV(knn, param_grid=params, cv=5, n_jobs=-1)
grid_cv.fit( X_train_minMax, y_train )
print("최적의 하이퍼 파라미터 : ", grid_cv.best_params_ )
print( grid_cv.score( X_train_minMax, y_train ) )
print( grid_cv.score( X_test_minMax, y_test ) )
최적의 하이퍼 파라미터 : {'metric': 'manhattan', 'n_neighbors': 4, 'weights': 'uniform'}
0.8665730337078652
0.8379888268156425
In [33]:
knn = KNeighborsClassifier(n_neighbors=3, metric="manhattan", weights="uniform")
knn.fit( X_train_minMax, y_train )
print( knn.score( X_train_minMax, y_train ) )
print( knn.score( X_test_minMax, y_test ) )
0.8834269662921348 0.8268156424581006
In [ ]:
In [ ]:
랜덤 포레스트 하이퍼 파라미터¶
- n_estimators
- 트리의 개수. default=10
- 트리의 개수가 많이면 성능은 좋아지지만, 시간이 오래 걸릴수 있다.
- max_depth
- 트리의 최대 깊이. default = None
- 완벽하게 파라미터값이 결정될 때 까지 분할 또는 min_samples_split보자 작아질 때까지 분할
- 깊이가 깊어지면 과대적합될 수 있으므로 적절히 제어 필요
- min_samples_leaf
- 맆노드(자식노드가 없는 노드)가 되기 위해 최소한의 샘플 데이터 수
- min_samples_split과 함께 과대적합 제어용도
- 불균형 데이터가 있는 경우 작게 설정하는게 좋다

In [34]:
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv("../data_set/5.스케일링/titanic_cleaning.csv")
df.head()
Out[34]:
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 22.0 | 1 | 0 | 7.2500 |
| 1 | 2 | 1 | 1 | 1 | 38.0 | 1 | 0 | 71.2833 |
| 2 | 3 | 1 | 3 | 1 | 26.0 | 0 | 0 | 7.9250 |
| 3 | 4 | 1 | 1 | 1 | 35.0 | 1 | 0 | 53.1000 |
| 4 | 5 | 0 | 3 | 0 | 35.0 | 0 | 0 | 8.0500 |
In [35]:
df.columns
Out[35]:
Index(['PassengerId', 'Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch',
'Fare'],
dtype='object')
In [36]:
f = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']
label = "Survived"
X, y = df[f], df[label]
In [37]:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
print("train : ", rfc.score(X_train, y_train))
print("test : ", rfc.score(X_test, y_test))
train : 0.9873595505617978 test : 0.8324022346368715
In [43]:
rfc = RandomForestClassifier(n_estimators=10, max_depth=10000, min_samples_leaf=10)
rfc.fit(X_train, y_train)
print("train : ", rfc.score(X_train, y_train))
print("test : ", rfc.score(X_test, y_test))
train : 0.8581460674157303 test : 0.8212290502793296
In [45]:
params = {
"n_estimators" : range(10, 101, 10),
"max_depth" : range(4, 11, 2),
"min_samples_leaf" : range(5, 21, 5)
}
rfc = RandomForestClassifier()
grid_cv = GridSearchCV( rfc, param_grid=params, cv=3, n_jobs=-1 )
grid_cv.fit( X_train, y_train )
print("최적의 하이퍼파라미터 : ", grid_cv.best_params_)
print("train : ", grid_cv.score(X_train, y_train))
print("test : ", grid_cv.score(X_test, y_test))
최적의 하이퍼파라미터 : {'max_depth': 8, 'min_samples_leaf': 5, 'n_estimators': 50}
train : 0.8764044943820225
test : 0.8156424581005587
In [46]:
grid_cv.predict( X_train )
Out[46]:
array([1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1,
0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0,
1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1,
0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0,
0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0,
0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1,
0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1,
0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1,
0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0,
1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0,
0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,
0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1,
1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1,
1, 0, 0, 0, 1, 0, 0, 1], dtype=int64)
In [ ]:
In [ ]:
하이퍼파라미터¶
- n_estimators
- 학습기의 수 설정.
- 많으면 예측률은 올라가나 시간이 오래걸릴 수 있음.
- learning_rate
- GBM이 학습을 진행할 때마다 적용하는 학습률로서 순차적으로 오류 값을 보정해가는 데 적용하는 수 이다
- 0~1 사이의 값으로 지정한다. default=0.1
- 너무 작은 값이면 업데이트를 너무 많이 하게 되어 꼼꼼하지만 시간이 오래 걸린다
- 너무 큰 값이면 최소 오류 값을 찾지 못할 수 있지만 빠르다
- subsample
- 학습기가 학습에 사용하는 데이터 샘플의 비율(0~1). default=1.
- 0.5일경우 50%학습데이터를 사용한다는 것이다
- 과대적합을 줄이려면 작은 값을 적용해야 한다.
In [47]:
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier()
gb.fit(X_train, y_train)
print("train : ", gb.score(X_train, y_train))
print("test : ", gb.score(X_test, y_test))
train : 0.9044943820224719 test : 0.8212290502793296
In [54]:
gb = GradientBoostingClassifier( learning_rate=0.1, n_estimators=100, subsample=0.9 )
gb.fit(X_train, y_train)
print("train : ", gb.score(X_train, y_train))
print("test : ", gb.score(X_test, y_test))
train : 0.9058988764044944 test : 0.8324022346368715
In [59]:
import numpy as np
params = {
"learning_rate" :[0.1, 0.3, 0.5, 0.7, 0.9],
"n_estimators" : [100, 200, 300, 400, 500],
"subsample" : np.arange(0.1, 1, 0.2)
}
gb = GradientBoostingClassifier()
grid_cv = GridSearchCV( gb, param_grid=params, cv=3, n_jobs=-1 )
grid_cv.fit(X_train, y_train)
print("파라미터 : ", grid_cv.best_params_)
print("train : ", grid_cv.score(X_train, y_train))
print("test : ", grid_cv.score(X_test, y_test))
파라미터 : {'learning_rate': 0.1, 'n_estimators': 100, 'subsample': 0.5000000000000001}
train : 0.898876404494382
test : 0.8491620111731844
728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 변수 선택법 ( feature selection ) (0) | 2024.05.28 |
|---|---|
| [머신러닝] 회귀 및 평가지표 (0) | 2024.05.27 |
| [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 (0) | 2024.05.24 |
| [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) (0) | 2024.05.24 |
| [머신러닝] 시각화 ( mataplotlib, seaborn ) (0) | 2024.05.24 |
[머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법
2024. 5. 24. 15:20
지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법
- 사용 이미지들 -
사용된 이미지가 많으므로 pdf 파일을 다운로드 받아서 봐야한다
분류, 회귀, 평가지표.pdf
4.87MB
Untitled.ipynb
0.05MB
Untitled.html
0.37MB
실습 예제 모음
혹시 몰라 HTML 형식으로도 업로드...
머신러닝 종류¶
- 지도학습 알고리즘
- 주요 목적은 레이블(정답)이 있는 훈련 데이터로 모델을 학습하여 예측할 때 사용
- 분류(classification)
- 독립변수(문제)에 의하여 종속변수(정답)가 딱 떨어지는 값일 때
- 예) 스펨메일, 은행에서 대출 승인/거절, 생존 중 살았다/죽었다. 등..
- 회귀(regression)
- 임의의 숫자를 맞추는 것.
- 어떤 사람의 나이, 농작물의 수확량, 주가 가격 등을 예측

In [ ]:
In [ ]:
사이킷 런¶
- 사이킷런은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리
- 파이썬 기반의 머신러닝을 위한 가장 쉽고 효율적인 개발 라이브러리를 제공
- 많은 사용자 들이 사용하는 라이브러리로 검증되어 있다
알고리즘 선택 방법¶
- 사이킷런에서 알고리즘 선택방법을 제시하고 있다
- https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html


In [ ]:
In [ ]:
Kneighbors(K-최근접 이웃 알고리즘)¶
- 주위의 가장 가까운 다른 데이터를 보고 현재 데이터를 판단
- 기본 비교 개수는 5개로 되어 있다
- 비교 개수를 변경하고자 할 경우 n_neighbors에 값 지정

In [ ]:
In [ ]:
Ensemble(앙상블)¶
- 여러 개의 분류기(알고리즘)를 생성하고 그 예측을 결합함으로써 보다 정확한 분류기 생성
- 앙상블의 대표 알고리즘은 랜덤포레스트와 그래디언트부스팅이 있다
- 앙상블 학습의 유형
- 보팅(Voting) : 서로 다른 알고리즘을 가진 분류기를 결합하여 사용
- 배깅(Bagging) : 모두 같은 유형의 알고리즘을 가진 분류기를 결합하여 사용
- 대표적 알고리즘인 랜덤포레스트가 있다
- 부스팅(Boosting) : 오류를 개선해 나가면서 학습하는 방식(다른 알고리즘에 비해 시간이 더 걸림)


In [ ]:
In [ ]:
train_test_split¶
- 데이터를 알고리즘에 사용하고자 하는경우 속성(feature)과 정답(label) 구분을 해야 한다.
- 알고리즘에 학습하기 위해 test data 와 train data를 구분하여 사용한다.
- 70% train(학습)데이터, 30% test 데이터(실제 데이터로 가정하여 확인)
- 20% test 데이터 , 80% -> 20%(validation)검증, 80% 학습데이터
In [ ]:
In [ ]:
사과 품질 분류하기¶
- 컬럼
- Size : 크기
- Weight : 무게
- Sweetness : 단맛
- Crunchiness : 아삭한 정도
- Juiciness : 사과 즙의 정도
- Ripeness : 사과의 숙성 정도
- Acidity : 신맛
- Quality : 품질
In [5]:
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
In [6]:
df = pd.read_csv("../data_set/4.분류/apple_quality.csv")
df.head()
Out[6]:
| A_id | Size | Weight | Sweetness | Crunchiness | Juiciness | Ripeness | Acidity | Quality | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -3.970049 | -2.512336 | 5.346330 | -1.012009 | 1.844900 | 0.329840 | -0.491590483 | good |
| 1 | 1.0 | -1.195217 | -2.839257 | 3.664059 | 1.588232 | 0.853286 | 0.867530 | -0.722809367 | good |
| 2 | 2.0 | -0.292024 | -1.351282 | -1.738429 | -0.342616 | 2.838636 | -0.038033 | 2.621636473 | bad |
| 3 | 3.0 | -0.657196 | -2.271627 | 1.324874 | -0.097875 | 3.637970 | -3.413761 | 0.790723217 | good |
| 4 | 4.0 | 1.364217 | -1.296612 | -0.384658 | -0.553006 | 3.030874 | -1.303849 | 0.501984036 | good |
In [7]:
df["Quality"].unique()
Out[7]:
array(['good', 'bad', nan], dtype=object)
In [10]:
df.isnull().sum()
Out[10]:
A_id 1 Size 1 Weight 1 Sweetness 1 Crunchiness 1 Juiciness 1 Ripeness 1 Acidity 0 Quality 1 dtype: int64
In [11]:
df.shape
Out[11]:
(4001, 9)
In [12]:
# 결측치가 있는 행을 모두 삭제
df.dropna(axis=0, inplace=True)
In [14]:
# 삭제 완료
df.isnull().sum()
Out[14]:
A_id 0 Size 0 Weight 0 Sweetness 0 Crunchiness 0 Juiciness 0 Ripeness 0 Acidity 0 Quality 0 dtype: int64
In [15]:
df.columns
Out[15]:
Index(['A_id', 'Size', 'Weight', 'Sweetness', 'Crunchiness', 'Juiciness',
'Ripeness', 'Acidity', 'Quality'],
dtype='object')
In [17]:
# 변수 ( features )
f = ['Size', 'Weight', 'Sweetness', 'Crunchiness', 'Juiciness',
'Ripeness', 'Acidity']
# 정답 ( label )
l = 'Quality'
X, y = df[f], df[l]
X, y
Out[17]:
( Size Weight Sweetness Crunchiness Juiciness Ripeness \
0 -3.970049 -2.512336 5.346330 -1.012009 1.844900 0.329840
1 -1.195217 -2.839257 3.664059 1.588232 0.853286 0.867530
2 -0.292024 -1.351282 -1.738429 -0.342616 2.838636 -0.038033
3 -0.657196 -2.271627 1.324874 -0.097875 3.637970 -3.413761
4 1.364217 -1.296612 -0.384658 -0.553006 3.030874 -1.303849
... ... ... ... ... ... ...
3995 0.059386 -1.067408 -3.714549 0.473052 1.697986 2.244055
3996 -0.293118 1.949253 -0.204020 -0.640196 0.024523 -1.087900
3997 -2.634515 -2.138247 -2.440461 0.657223 2.199709 4.763859
3998 -4.008004 -1.779337 2.366397 -0.200329 2.161435 0.214488
3999 0.278540 -1.715505 0.121217 -1.154075 1.266677 -0.776571
Acidity
0 -0.491590483
1 -0.722809367
2 2.621636473
3 0.790723217
4 0.501984036
... ...
3995 0.137784369
3996 1.854235285
3997 -1.334611391
3998 -2.229719806
3999 1.599796456
[4000 rows x 7 columns],
0 good
1 good
2 bad
3 good
4 good
...
3995 bad
3996 good
3997 bad
3998 good
3999 good
Name: Quality, Length: 4000, dtype: object)
In [18]:
from sklearn.model_selection import train_test_split
# 학습용 70프로 할당
# 테스트용 30프로 할당
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
In [20]:
print("총 갯수 : ", X.shape, y.shape)
print("학습 갯수 : ", X_train.shape, y_train.shape)
print("테스트 갯수 : ", X_test.shape, y_test.shape)
총 갯수 : (4000, 7) (4000,) 학습 갯수 : (2800, 7) (2800,) 테스트 갯수 : (1200, 7) (1200,)
In [23]:
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
# 문제와 정답 학습시키기
kn.fit(X_train, y_train)
# 테스트용으로 예측한 정답과 실제 정답을 비교한
# 정답률을 확인
# 90% 정답률 확인
kn.score(X_test, y_test)
Out[23]:
0.9083333333333333
In [ ]:
In [ ]:
SVM(Support Vector Machine)¶
- 특정 데이터들을 구분하는 선을 찾고, 이를 기반으로 패턴을 인식하는 방법
- kernel : linear, rbf
- linear : 선형으로 데이터들을 구분지을 수 있는 경우
- rbf : 선형으로 데이터를 구분지을 수 없는 경우

In [29]:
import sklearn.svm as svm
# linear(선형) 구조로 알고리즘을 학습
svm_linear = svm.SVC(kernel="linear")
# SVM 알고리즘을 사용하여 학습
svm_linear.fit(X_train, y_train)
# 테스트 결과
svm_linear.score(X_test, y_test)
Out[29]:
0.7516666666666667
In [30]:
import sklearn.svm as svm
# rbf(비선형) 구조로 알고리즘을 학습
svm_linear = svm.SVC(kernel="rbf")
# SVM 알고리즘을 사용하여 학습
svm_linear.fit(X_train, y_train)
# 테스트 결과
svm_linear.score(X_test, y_test)
Out[30]:
0.9091666666666667
In [31]:
# 학습 결과 비선형 알고리즘이 해당 데이터에서는
# 더 정확한 예측 값을 가져오므로 비선형 알고리즘을
# 사용해야 한다.... 라는 결론 도출
In [ ]:
In [ ]:
DecisionTree¶
- 특정 조건에 따라 가지치기 과정을 반복하면서 모델을 생성한다

In [33]:
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
# 학습
dt.fit(X_train, y_train)
# 정확도 확인
dt.score(X_test, y_test)
Out[33]:
0.82
In [ ]:
In [ ]:
Voting(보팅)¶
- 하드보팅(Hard Voting) : 다수의 결정에 의해 결과값이 선정된다
- 소프트보팅(Soft Voting) : 결정된 값들의 평균을 구하고 가장 높은 값을 선정
- 일반적으로 하드보팅보다 소프트 보팅이 성능이 좋아 소프트 보팅을 많이 사용한다
In [35]:
# probability=True : soft voting 시 참, 거짓이 아닌 확률을 참 : 70%, 거짓 : 30%
# 확률로 나타내준다
s = svm.SVC( kernel="rbf", probability=True )
s.fit(X_train, y_train)
k = KNeighborsClassifier()
k.fit(X_train, y_train)
d = DecisionTreeClassifier()
d.fit(X_train, y_train)
Out[35]:
DecisionTreeClassifier()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier()
In [40]:
from sklearn.ensemble import VotingClassifier
# VotinClassifier 객체를 생성하여 각 알고리즘을 추합해서
# 알고리즘의 예측 값들을 가져와 결론을 도출할 수 있다
# soft voting 설정
vo = VotingClassifier( estimators=[("svc",s), ("knn",k), ("DecisionTree",d)], voting="soft")
vo.fit(X_train, y_train)
print("svm : ", s.score(X_test, y_test))
print("kn : ", k.score(X_test, y_test))
print("d : ", d.score(X_test, y_test))
print("vo : ", vo.score(X_test, y_test))
svm : 0.9091666666666667 kn : 0.9083333333333333 d : 0.8125 vo : 0.8933333333333333
In [41]:
# VotinClassifier 객체를 생성하여 각 알고리즘을 추합해서
# 알고리즘의 예측 값들을 가져와 결론을 도출할 수 있다
# hard voting 설정
vo = VotingClassifier( estimators=[("svc",s), ("knn",k), ("DecisionTree",d)], voting="hard")
vo.fit(X_train, y_train)
print("svm : ", s.score(X_test, y_test))
print("kn : ", k.score(X_test, y_test))
print("d : ", d.score(X_test, y_test))
print("vo : ", vo.score(X_test, y_test))
svm : 0.9091666666666667 kn : 0.9083333333333333 d : 0.8125 vo : 0.9075
In [ ]:
In [ ]:
RandomForest(랜덤포레스트)¶
- decision tree 알고리즘을 여러 개의 분류기로 만들어서 보팅(소프트보팅)으로 최종 결정한다
In [43]:
from sklearn.ensemble import RandomForestClassifier
# 모델 생성
rfc = RandomForestClassifier()
# 모델 학습
rfc.fit(X_train, y_train)
# 학습 결과 테스트
rfc.score(X_test, y_test)
Out[43]:
0.8991666666666667
In [ ]:
In [ ]:
부스팅(Boosting)¶
- GBM(Gradient Boosting Machine)
- decision tree를 묶어 강력한 model을 만드는 ensemble기법입니다.
- 순차적으로 학습-예측하면서 잘못 예측한 데이터의 오류를 개선해 나가면서 학습하는 방법
- 다른 알고리즘에 비해 처리속도가 느림

In [44]:
from sklearn.ensemble import GradientBoostingClassifier
# 모델 생성
gbc = GradientBoostingClassifier()
# 모델 학습
gbc.fit(X_train, y_train)
# 학습 결과 테스트
gbc.score(X_test, y_test)
Out[44]:
0.8666666666666667
In [ ]:
In [ ]:
In [45]:
df.head(2)
Out[45]:
| A_id | Size | Weight | Sweetness | Crunchiness | Juiciness | Ripeness | Acidity | Quality | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -3.970049 | -2.512336 | 5.346330 | -1.012009 | 1.844900 | 0.32984 | -0.491590483 | good |
| 1 | 1.0 | -1.195217 | -2.839257 | 3.664059 | 1.588232 | 0.853286 | 0.86753 | -0.722809367 | good |
In [49]:
s.predict([[-3.970049, -2.512336, 5.346330, -1.012009, 1.844900, 0.32984, -0.491590483]])
Out[49]:
array(['good'], dtype=object)
In [ ]:
In [ ]:
Classification Metric¶
- Metric : 학습을 통해 목표를 얼마나 잘(못) 달성했는지를 나타내는 값을 척도(metric)라고 합니다
- Accuracy(정확도)
- 전체 샘플 중 맞게 예측한 샘플 수의 비율
- Recall(재현율)
- 양성 샘플을 양성으로 맞춘 비율과 양성을 음성으로 잘못 예측한 비율
- 실제 음성을 양성으로 잘못 맞춰도 재현율은 떨어지지 않는다
- Precision(정밀도)
- 양성이라고 예측한 값의 비례하는 실제 값이 양성인 비율
- 음성을 양성으로 잘못 판단하면 정밀도는 떨어진다
- F1 - score
- Reacll과 Precision의 조화평균
- Accuracy(정확도)
Accuracy(정확도)¶
- 전체 샘플 중 맞게 예측한 샘플 수의 비율을 뜻한다.
- 즉, 전체 개수 중 정답을 맞춘 개수이다.
- 10문제 중 8개 맞추면 80% 맞춘 결과가 나온다
- accuracy는 label의 값이 균등할 때 사용하면 된다.
In [50]:
y_test = [0,1,1,0,0,0,1,1,1,1] #실제 정답
y_pred = [1,0,0,0,0,0,1,1,1,1] #예측 정답
In [53]:
from sklearn.metrics import accuracy_score
# 단순히 몇개를 맞췄는지 확인하는 accuracy_score
# 아래와 같이 사용하면 % 로 정답률을 알려줌
acc = accuracy_score(y_test, y_pred)
acc
Out[53]:
0.8
In [55]:
# 암인지 아닌지에 대한 Dataset
# 1 : 암에 걸림, 0 : 암에 걸리지 않음
y_test = [1,1,0,1,1,1,1,1,1,1] #실제 정답
y_pred = [0,1,1,1,1,1,1,1,1,1] #예측 정답
In [57]:
# 80% 정답률을 확인
acc = accuracy_score(y_test, y_pred)
acc
Out[57]:
0.8
In [ ]:
In [ ]:
재현율(recall)¶
- 실제 양성 샘플을 양성으로 맞춘 비율과 양성을 음성으로 잘못 예측한 비율
- 높을 수록 좋은 모델
- 양성(1)이 중요한 경우
In [62]:
y_test = [0,0,0,1,1,1,1,1,1,1] #실제 정답
y_pred = [1,1,1,1,1,1,1,1,1,1] #예측 정답
In [64]:
from sklearn.metrics import recall_score
# 모델 생성 및 훈련
recall = recall_score(y_test, y_pred)
recall
# 실제 정답이 1 즉, 의미 있는 결과 값이 나온것에 대한
# 정답률만을 출력....
# 0 에 대한 정답률은 출력하지 않음
# 고로 0 : 암에 걸리지 않음, 1 : 암에 걸림 이라면
# 암에 걸린 사람들에 대한 예측 결과만 100% 로 맞추고
# 암에 걸리지 않은 사람들에 대한 예측결과는 50% 로 맞췄다면
# 결과는 100% 로 출력된다
Out[64]:
1.0
In [65]:
y_test = [1,1,1,1,1,1,1,1,1,1] #실제 스팸 문자
y_pred = [0,0,0,1,1,1,1,1,1,1] #예측 스팸 문자
recall = recall_score(y_test, y_pred)
recall
Out[65]:
0.7
In [67]:
y_test = [0,0,0,1,1,1,1,1,1,1] #실제 스팸 문자
y_pred = [1,1,1,1,1,1,1,1,1,1] #예측 스팸 문자
recall = recall_score(y_test, y_pred)
recall
# 메일의 경우는 recall 로 처리하면 안된다...
# 정답률이 100% 로 나오기 때문에 실제 스팸 문자가 아닌데
# 스팸 문자로 처리될 수 있기 때문...!!!
Out[67]:
1.0
In [ ]:
In [ ]:
정밀도(precision)¶
- 실제 음성의 값을 못맞추는 경우 예측력이 떨어진다\
In [70]:
y_test = [1,1,1,1,1,1,1,1,1,1] #실제 스팸 문자
y_pred = [0,0,0,1,1,1,1,1,1,1] #예측 스팸 문자
In [72]:
from sklearn.metrics import precision_score
p = precision_score(y_test, y_pred)
p
# 정밀도를 기준으로 판단은 예측 값이 1인 경우의 정답률만을 확인
# 고로, 예측한 스팸 문자가 실제로 스팸문자 인지만 확인하여
# 정답률을 출력한다....
# 스팸메일이 아닌 문자로 예측한 문자에 대한 정답률은 확인하지 않는다
Out[72]:
1.0
In [76]:
y_test = [0,0,1,1,1,1,1,1,1,1] #실제 스팸 문자
y_pred = [1,1,0,1,1,1,1,1,1,1] #예측 스팸 문자
p = precision_score(y_test, y_pred)
p
# 스팸문자라고 예측한 값이 실제 스팸문자가 아닌 경우가 생겼기 때문에
# 예측 정답률이 1.0 이 아니게 된다
Out[76]:
0.7777777777777778
In [ ]:
In [ ]:
In [77]:
y_test = [0,0,1,1,1,1,1,1,1,1] #실제 스팸 문자
y_pred = [1,1,1,1,1,1,1,1,1,1] #예측 스팸 문자
In [80]:
from sklearn.metrics import f1_score
acc = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
pre = precision_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print("accuracy(정확도) : ", acc)
print("recall(재현율) : ", recall)
print("precision(정밀도) : ", pre)
print("f1 score : ", f1)
# f1 은 recall 과 precision 의 결과를 혼합해서 정답률을 출력한다
accuracy(정확도) : 0.8 recall(재현율) : 1.0 precision(정밀도) : 0.8 f1 score : 0.888888888888889
In [ ]:
평가지표 선택하기¶
- accuracy : label값이 편향되어 있지 않은 경우
- f1_score : label값이 편향되어 있는 경우
정답 값이 편향되어 있는 경우 f1_score 을 사용
정답 값이 편향되어 있지 않고 42% : 58% 같이 균형을 이룬 경우 accuracy 사용경우
728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 회귀 및 평가지표 (0) | 2024.05.27 |
|---|---|
| [머신러닝] 과적합 및 하이퍼파라미터 (0) | 2024.05.27 |
| [머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 ) (0) | 2024.05.24 |
| [머신러닝] 시각화 ( mataplotlib, seaborn ) (0) | 2024.05.24 |
| [머신러닝] 실습 예제 및 풀이 (1) | 2024.05.23 |
[머신러닝] 탐색적 데이터분석 ( EDA, 표준화, 가중치 )
2024. 5. 24. 13:20
탐색적 데이터 분석 ( DEA, 표준화, 가중치 )
2. 탐색적 데이터분석(EDA).html
0.53MB
2. 탐색적 데이터분석(EDA).ipynb
0.31MB
In [1]:
import pandas as pd
In [15]:
# sep = "\t" : tab 을 기준으로 데이터를 가지고 옴
df = pd.read_csv("../data_set/3.시각화/report.txt", sep="\t")
df.head()
Out[15]:
| 기간 | 대분류 | 분류 | 운동을 할 충분한 시간이 없어서 | 함께 운동을 할 사람이 없어서 | 운동을 할 만한 장소가 없어서 | 운동을 싫어해서 | 운동을 할 충분한 비용이 없어서 | 기타 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019 | 서울시 | 서울시 | 46.8 | 5.0 | 4.3 | 37.3 | 5.2 | 1.4 |
| 1 | 2019 | 성별 | 남자 | 52.4 | 4.4 | 4.9 | 32.4 | 4.9 | 1.1 |
| 2 | 2019 | 성별 | 여자 | 42.5 | 5.6 | 3.9 | 41.0 | 5.4 | 1.7 |
| 3 | 2019 | 연령별 | 10대 | 55.3 | 4.8 | 3.9 | 32.6 | 3.5 | - |
| 4 | 2019 | 연령별 | 20대 | 46.0 | 4.2 | 4.5 | 38.8 | 6.4 | 0.1 |
In [6]:
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 52 entries, 0 to 51 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 기간 52 non-null int64 1 대분류 52 non-null object 2 분류 52 non-null object 3 운동을 할 충분한 시간이 없어서 52 non-null float64 4 함께 운동을 할 사람이 없어서 52 non-null float64 5 운동을 할 만한 장소가 없어서 52 non-null float64 6 운동을 싫어해서 52 non-null float64 7 운동을 할 충분한 비용이 없어서 52 non-null float64 8 기타 52 non-null object dtypes: float64(5), int64(1), object(3) memory usage: 3.8+ KB
In [7]:
# 각 컬럼의 결측치 값의 갯수 확인
df.isnull().sum()
Out[7]:
기간 0 대분류 0 분류 0 운동을 할 충분한 시간이 없어서 0 함께 운동을 할 사람이 없어서 0 운동을 할 만한 장소가 없어서 0 운동을 싫어해서 0 운동을 할 충분한 비용이 없어서 0 기타 0 dtype: int64
In [10]:
df.describe()
Out[10]:
| 기간 | 운동을 할 충분한 시간이 없어서 | 함께 운동을 할 사람이 없어서 | 운동을 할 만한 장소가 없어서 | 운동을 싫어해서 | 운동을 할 충분한 비용이 없어서 | |
|---|---|---|---|---|---|---|
| count | 52.0 | 52.000000 | 52.000000 | 52.000000 | 52.000000 | 52.000000 |
| mean | 2019.0 | 46.267308 | 5.103846 | 4.655769 | 37.153846 | 5.163462 |
| std | 0.0 | 10.723709 | 2.211109 | 1.868145 | 8.666217 | 2.020001 |
| min | 2019.0 | 10.700000 | 0.400000 | 1.200000 | 17.900000 | 0.900000 |
| 25% | 2019.0 | 42.775000 | 4.125000 | 3.300000 | 32.550000 | 4.075000 |
| 50% | 2019.0 | 46.900000 | 4.850000 | 4.400000 | 35.850000 | 5.250000 |
| 75% | 2019.0 | 52.100000 | 6.050000 | 5.700000 | 39.775000 | 6.250000 |
| max | 2019.0 | 69.800000 | 13.900000 | 9.900000 | 68.100000 | 10.900000 |
In [13]:
# 컬럼 확인
# 운동을 할 충분한 시간이 없어서, 함께 운동을 할 사람이 없어서 컬럼 등은
# 내가 운동시설을 만든다고 가정할 때 중요한 컬럼이 아니기 때문에 제거할 것임
df.columns
Out[13]:
Index(['기간', '대분류', '분류', '운동을 할 충분한 시간이 없어서', '함께 운동을 할 사람이 없어서',
'운동을 할 만한 장소가 없어서', '운동을 싫어해서', '운동을 할 충분한 비용이 없어서', '기타'],
dtype='object')
In [16]:
# 사용하지 않을 컬럼을 label 에 저장
label = ['기간', '분류', '운동을 할 충분한 시간이 없어서', '함께 운동을 할 사람이 없어서',
'운동을 싫어해서', '기타']
# axis=1 로 label 에 들어있는 값을 가진 열을 삭제
df.drop(labels=label, axis=1, inplace=True)
df.columns
Out[16]:
Index(['대분류', '운동을 할 만한 장소가 없어서', '운동을 할 충분한 비용이 없어서'], dtype='object')
In [17]:
df['대분류']
Out[17]:
0 서울시 1 성별 2 성별 3 연령별 4 연령별 5 연령별 6 연령별 7 연령별 8 연령별 9 학력별 10 학력별 11 학력별 12 학력별 13 소득별 14 소득별 15 소득별 16 소득별 17 소득별 18 소득별 19 혼인상태별 20 혼인상태별 21 혼인상태별 22 지역대분류 23 지역대분류 24 지역대분류 25 지역대분류 26 지역대분류 27 종로구 28 중구 29 용산구 30 성동구 31 광진구 32 동대문구 33 중랑구 34 성북구 35 강북구 36 도봉구 37 노원구 38 은평구 39 서대문구 40 마포구 41 양천구 42 강서구 43 구로구 44 금천구 45 영등포구 46 동작구 47 관악구 48 서초구 49 강남구 50 송파구 51 강동구 Name: 대분류, dtype: object
In [20]:
# 대분류의 값이 "구" 로 끝나는 문자가 아닌 값을 가져와라
# ~ 를 앞에 사용하여 "구"로 끝나는 문자가 아닌 것들을 가져옴
del_index = df[ ~df['대분류'].str.endswith("구")].index
del_index
Out[20]:
Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26],
dtype='int64')
In [23]:
df.loc[ del_index ]
Out[23]:
| 대분류 | 운동을 할 만한 장소가 없어서 | 운동을 할 충분한 비용이 없어서 | |
|---|---|---|---|
| 0 | 서울시 | 4.3 | 5.2 |
| 1 | 성별 | 4.9 | 4.9 |
| 2 | 성별 | 3.9 | 5.4 |
| 3 | 연령별 | 3.9 | 3.5 |
| 4 | 연령별 | 4.5 | 6.4 |
| 5 | 연령별 | 2.9 | 4.5 |
| 6 | 연령별 | 2.9 | 3.3 |
| 7 | 연령별 | 4.5 | 5.6 |
| 8 | 연령별 | 6.6 | 6.6 |
| 9 | 학력별 | 4.8 | 7.3 |
| 10 | 학력별 | 5.6 | 5.5 |
| 11 | 학력별 | 3.3 | 4.6 |
| 12 | 학력별 | 5.6 | 0.9 |
| 13 | 소득별 | 9.9 | 9.4 |
| 14 | 소득별 | 6.0 | 7.4 |
| 15 | 소득별 | 3.9 | 5.1 |
| 16 | 소득별 | 4.2 | 4.8 |
| 17 | 소득별 | 3.3 | 5.3 |
| 18 | 소득별 | 4.0 | 4.5 |
| 19 | 혼인상태별 | 4.1 | 4.6 |
| 20 | 혼인상태별 | 4.0 | 5.6 |
| 21 | 혼인상태별 | 5.7 | 6.4 |
| 22 | 지역대분류 | 7.2 | 4.0 |
| 23 | 지역대분류 | 4.1 | 5.5 |
| 24 | 지역대분류 | 5.1 | 5.3 |
| 25 | 지역대분류 | 4.7 | 4.8 |
| 26 | 지역대분류 | 3.1 | 5.4 |
In [24]:
# 대분류 컬럼의 "구" 로 끝나지 않는 행을 모두 삭제
df.drop( del_index, inplace=True )
df
Out[24]:
| 대분류 | 운동을 할 만한 장소가 없어서 | 운동을 할 충분한 비용이 없어서 | |
|---|---|---|---|
| 27 | 종로구 | 9.4 | 2.1 |
| 28 | 중구 | 7.7 | 7.6 |
| 29 | 용산구 | 4.9 | 2.7 |
| 30 | 성동구 | 5.7 | 8.7 |
| 31 | 광진구 | 3.0 | 5.8 |
| 32 | 동대문구 | 2.7 | 6.2 |
| 33 | 중랑구 | 6.8 | 10.9 |
| 34 | 성북구 | 2.6 | 2.0 |
| 35 | 강북구 | 3.4 | 1.9 |
| 36 | 도봉구 | 6.2 | 7.6 |
| 37 | 노원구 | 2.7 | 1.9 |
| 38 | 은평구 | 7.3 | 6.4 |
| 39 | 서대문구 | 1.2 | 5.3 |
| 40 | 마포구 | 4.7 | 3.2 |
| 41 | 양천구 | 5.9 | 4.1 |
| 42 | 강서구 | 1.9 | 4.3 |
| 43 | 구로구 | 5.8 | 2.9 |
| 44 | 금천구 | 2.3 | 2.3 |
| 45 | 영등포구 | 3.8 | 5.4 |
| 46 | 동작구 | 8.4 | 7.6 |
| 47 | 관악구 | 5.5 | 6.1 |
| 48 | 서초구 | 4.1 | 3.3 |
| 49 | 강남구 | 2.0 | 5.2 |
| 50 | 송파구 | 2.3 | 4.8 |
| 51 | 강동구 | 4.8 | 8.4 |
In [26]:
# 대분류에 중복된 데이터의 합을 구해옴
# 결과가 0 이므로 대분류 컬럼엔 중복된 데이터가 없음
df["대분류"].duplicated().sum()
Out[26]:
0
In [28]:
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rc("font", family="Malgun Gothic")
In [53]:
fig, ax = plt.subplots(2,1, figsize=(10,7))
g = sns.barplot( x="대분류", y="운동을 할 만한 장소가 없어서", data=df, ax=ax[0], hue="대분류")
g.set_xticklabels(g.get_xticklabels(), rotation = 30)
g1 = sns.barplot( x="대분류", y="운동을 할 충분한 비용이 없어서", data=df, ax=ax[1], palette="rainbow")
g1.set_xticklabels(g.get_xticklabels(), rotation = 30)
plt.show()

In [56]:
# 운동을 할 만한 장소가 없어서의 데이터를 내림차순 하여 넣어주겠ek
df_sort = df.sort_values(by=["운동을 할 만한 장소가 없어서"], axis=0, ascending=False)
df_sort
Out[56]:
| 대분류 | 운동을 할 만한 장소가 없어서 | 운동을 할 충분한 비용이 없어서 | |
|---|---|---|---|
| 27 | 종로구 | 9.4 | 2.1 |
| 46 | 동작구 | 8.4 | 7.6 |
| 28 | 중구 | 7.7 | 7.6 |
| 38 | 은평구 | 7.3 | 6.4 |
| 33 | 중랑구 | 6.8 | 10.9 |
| 36 | 도봉구 | 6.2 | 7.6 |
| 41 | 양천구 | 5.9 | 4.1 |
| 43 | 구로구 | 5.8 | 2.9 |
| 30 | 성동구 | 5.7 | 8.7 |
| 47 | 관악구 | 5.5 | 6.1 |
| 29 | 용산구 | 4.9 | 2.7 |
| 51 | 강동구 | 4.8 | 8.4 |
| 40 | 마포구 | 4.7 | 3.2 |
| 48 | 서초구 | 4.1 | 3.3 |
| 45 | 영등포구 | 3.8 | 5.4 |
| 35 | 강북구 | 3.4 | 1.9 |
| 31 | 광진구 | 3.0 | 5.8 |
| 37 | 노원구 | 2.7 | 1.9 |
| 32 | 동대문구 | 2.7 | 6.2 |
| 34 | 성북구 | 2.6 | 2.0 |
| 44 | 금천구 | 2.3 | 2.3 |
| 50 | 송파구 | 2.3 | 4.8 |
| 49 | 강남구 | 2.0 | 5.2 |
| 42 | 강서구 | 1.9 | 4.3 |
| 39 | 서대문구 | 1.2 | 5.3 |
In [58]:
df_sort.rename(columns={
df_sort.columns[0] : "분류",
df_sort.columns[1] : "장소부족",
df_sort.columns[2] : "비용부족"}, inplace=True )
df_sort
Out[58]:
| 분류 | 장소부족 | 비용부족 | |
|---|---|---|---|
| 27 | 종로구 | 9.4 | 2.1 |
| 46 | 동작구 | 8.4 | 7.6 |
| 28 | 중구 | 7.7 | 7.6 |
| 38 | 은평구 | 7.3 | 6.4 |
| 33 | 중랑구 | 6.8 | 10.9 |
| 36 | 도봉구 | 6.2 | 7.6 |
| 41 | 양천구 | 5.9 | 4.1 |
| 43 | 구로구 | 5.8 | 2.9 |
| 30 | 성동구 | 5.7 | 8.7 |
| 47 | 관악구 | 5.5 | 6.1 |
| 29 | 용산구 | 4.9 | 2.7 |
| 51 | 강동구 | 4.8 | 8.4 |
| 40 | 마포구 | 4.7 | 3.2 |
| 48 | 서초구 | 4.1 | 3.3 |
| 45 | 영등포구 | 3.8 | 5.4 |
| 35 | 강북구 | 3.4 | 1.9 |
| 31 | 광진구 | 3.0 | 5.8 |
| 37 | 노원구 | 2.7 | 1.9 |
| 32 | 동대문구 | 2.7 | 6.2 |
| 34 | 성북구 | 2.6 | 2.0 |
| 44 | 금천구 | 2.3 | 2.3 |
| 50 | 송파구 | 2.3 | 4.8 |
| 49 | 강남구 | 2.0 | 5.2 |
| 42 | 강서구 | 1.9 | 4.3 |
| 39 | 서대문구 | 1.2 | 5.3 |
In [ ]:
In [ ]:
MinMaxScaler(표준화)¶
- 모든 특성이 정확하게 0과 1사이에 위치하도록 데이터를 변경한다
- 가장 작은값을 0, 가장 큰값을 1로 두고 결과를 뽑아
- 영화평점을 매긴다고 할 때 naver 는 1-5점, daum 은 1-10 점을 부여할 수 있다고 가정하면
- 해당 범위를 표준화시켜서 계산해야 한다준다
In [59]:
df_sort.describe()
Out[59]:
| 장소부족 | 비용부족 | |
|---|---|---|
| count | 25.000000 | 25.000000 |
| mean | 4.604000 | 5.068000 |
| std | 2.230187 | 2.473648 |
| min | 1.200000 | 1.900000 |
| 25% | 2.700000 | 2.900000 |
| 50% | 4.700000 | 5.200000 |
| 75% | 5.900000 | 6.400000 |
| max | 9.400000 | 10.900000 |
In [60]:
from sklearn.preprocessing import MinMaxScaler
In [68]:
movie = {"daum" : [2, 4, 6, 8, 10], "naver" : [1, 3, 3, 2, 5]}
mv = pd.DataFrame(movie)
mv
Out[68]:
| daum | naver | |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 4 | 3 |
| 2 | 6 | 3 |
| 3 | 8 | 2 |
| 4 | 10 | 5 |
In [69]:
# 스케일을 표준화
min_max_scaler = MinMaxScaler()
mv_sc = min_max_scaler.fit_transform(mv)
mv_sc
Out[69]:
array([[0. , 0. ],
[0.25, 0.5 ],
[0.5 , 0.5 ],
[0.75, 0.25],
[1. , 1. ]])
In [71]:
# 표준화된 데이터 출력
pd.DataFrame(mv_sc, columns=["daum", "naver"])
Out[71]:
| daum | naver | |
|---|---|---|
| 0 | 0.00 | 0.00 |
| 1 | 0.25 | 0.50 |
| 2 | 0.50 | 0.50 |
| 3 | 0.75 | 0.25 |
| 4 | 1.00 | 1.00 |
In [73]:
# 데이터 표준화
min_max_s = MinMaxScaler()
min_max_df = min_max_s.fit_transform(df_sort[["장소부족", "비용부족"]])
min_max_df
Out[73]:
array([[1. , 0.02222222],
[0.87804878, 0.63333333],
[0.79268293, 0.63333333],
[0.74390244, 0.5 ],
[0.68292683, 1. ],
[0.6097561 , 0.63333333],
[0.57317073, 0.24444444],
[0.56097561, 0.11111111],
[0.54878049, 0.75555556],
[0.52439024, 0.46666667],
[0.45121951, 0.08888889],
[0.43902439, 0.72222222],
[0.42682927, 0.14444444],
[0.35365854, 0.15555556],
[0.31707317, 0.38888889],
[0.26829268, 0. ],
[0.2195122 , 0.43333333],
[0.18292683, 0. ],
[0.18292683, 0.47777778],
[0.17073171, 0.01111111],
[0.13414634, 0.04444444],
[0.13414634, 0.32222222],
[0.09756098, 0.36666667],
[0.08536585, 0.26666667],
[0. , 0.37777778]])
In [74]:
df_replace = pd.DataFrame(min_max_df, columns=["장소부족", "비용부족"])
df_replace
Out[74]:
| 장소부족 | 비용부족 | |
|---|---|---|
| 0 | 1.000000 | 0.022222 |
| 1 | 0.878049 | 0.633333 |
| 2 | 0.792683 | 0.633333 |
| 3 | 0.743902 | 0.500000 |
| 4 | 0.682927 | 1.000000 |
| 5 | 0.609756 | 0.633333 |
| 6 | 0.573171 | 0.244444 |
| 7 | 0.560976 | 0.111111 |
| 8 | 0.548780 | 0.755556 |
| 9 | 0.524390 | 0.466667 |
| 10 | 0.451220 | 0.088889 |
| 11 | 0.439024 | 0.722222 |
| 12 | 0.426829 | 0.144444 |
| 13 | 0.353659 | 0.155556 |
| 14 | 0.317073 | 0.388889 |
| 15 | 0.268293 | 0.000000 |
| 16 | 0.219512 | 0.433333 |
| 17 | 0.182927 | 0.000000 |
| 18 | 0.182927 | 0.477778 |
| 19 | 0.170732 | 0.011111 |
| 20 | 0.134146 | 0.044444 |
| 21 | 0.134146 | 0.322222 |
| 22 | 0.097561 | 0.366667 |
| 23 | 0.085366 | 0.266667 |
| 24 | 0.000000 | 0.377778 |
In [76]:
# min(최솟값), max(최댓값) 표준화 된 것 확인
# 둘 다 0, 1 로 변경
df_replace.describe()
Out[76]:
| 장소부족 | 비용부족 | |
|---|---|---|
| count | 25.000000 | 25.000000 |
| mean | 0.415122 | 0.352000 |
| std | 0.271974 | 0.274850 |
| min | 0.000000 | 0.000000 |
| 25% | 0.182927 | 0.111111 |
| 50% | 0.426829 | 0.366667 |
| 75% | 0.573171 | 0.500000 |
| max | 1.000000 | 1.000000 |
In [79]:
# 분류 값을 추가
df_replace = pd.DataFrame(min_max_df, columns=["장소부족", "비용부족"])
df_replace["분류"] = df_sort["분류"].values
df_replace
Out[79]:
| 장소부족 | 비용부족 | 분류 | |
|---|---|---|---|
| 0 | 1.000000 | 0.022222 | 종로구 |
| 1 | 0.878049 | 0.633333 | 동작구 |
| 2 | 0.792683 | 0.633333 | 중구 |
| 3 | 0.743902 | 0.500000 | 은평구 |
| 4 | 0.682927 | 1.000000 | 중랑구 |
| 5 | 0.609756 | 0.633333 | 도봉구 |
| 6 | 0.573171 | 0.244444 | 양천구 |
| 7 | 0.560976 | 0.111111 | 구로구 |
| 8 | 0.548780 | 0.755556 | 성동구 |
| 9 | 0.524390 | 0.466667 | 관악구 |
| 10 | 0.451220 | 0.088889 | 용산구 |
| 11 | 0.439024 | 0.722222 | 강동구 |
| 12 | 0.426829 | 0.144444 | 마포구 |
| 13 | 0.353659 | 0.155556 | 서초구 |
| 14 | 0.317073 | 0.388889 | 영등포구 |
| 15 | 0.268293 | 0.000000 | 강북구 |
| 16 | 0.219512 | 0.433333 | 광진구 |
| 17 | 0.182927 | 0.000000 | 노원구 |
| 18 | 0.182927 | 0.477778 | 동대문구 |
| 19 | 0.170732 | 0.011111 | 성북구 |
| 20 | 0.134146 | 0.044444 | 금천구 |
| 21 | 0.134146 | 0.322222 | 송파구 |
| 22 | 0.097561 | 0.366667 | 강남구 |
| 23 | 0.085366 | 0.266667 | 강서구 |
| 24 | 0.000000 | 0.377778 | 서대문구 |
In [82]:
# 컬럼의 순서를 변경하여 df_sort 에 저장
df_sort = df_replace[["분류", "장소부족", "비용부족"]]
df_sort
Out[82]:
| 분류 | 장소부족 | 비용부족 | |
|---|---|---|---|
| 0 | 종로구 | 1.000000 | 0.022222 |
| 1 | 동작구 | 0.878049 | 0.633333 |
| 2 | 중구 | 0.792683 | 0.633333 |
| 3 | 은평구 | 0.743902 | 0.500000 |
| 4 | 중랑구 | 0.682927 | 1.000000 |
| 5 | 도봉구 | 0.609756 | 0.633333 |
| 6 | 양천구 | 0.573171 | 0.244444 |
| 7 | 구로구 | 0.560976 | 0.111111 |
| 8 | 성동구 | 0.548780 | 0.755556 |
| 9 | 관악구 | 0.524390 | 0.466667 |
| 10 | 용산구 | 0.451220 | 0.088889 |
| 11 | 강동구 | 0.439024 | 0.722222 |
| 12 | 마포구 | 0.426829 | 0.144444 |
| 13 | 서초구 | 0.353659 | 0.155556 |
| 14 | 영등포구 | 0.317073 | 0.388889 |
| 15 | 강북구 | 0.268293 | 0.000000 |
| 16 | 광진구 | 0.219512 | 0.433333 |
| 17 | 노원구 | 0.182927 | 0.000000 |
| 18 | 동대문구 | 0.182927 | 0.477778 |
| 19 | 성북구 | 0.170732 | 0.011111 |
| 20 | 금천구 | 0.134146 | 0.044444 |
| 21 | 송파구 | 0.134146 | 0.322222 |
| 22 | 강남구 | 0.097561 | 0.366667 |
| 23 | 강서구 | 0.085366 | 0.266667 |
| 24 | 서대문구 | 0.000000 | 0.377778 |
In [85]:
# 장소부족을 60% 가중치, 비용부족을 40% 가중치를 부여하여
# 종합점수라는 컬럼을 생성하여 저장
df_sort["종합점수"] = df_sort["장소부족"] * 0.6 + df_sort["비용부족"] * 0.4
# 종합점수의 내림차순을 기준으로 정렬
df_sort.sort_values(by="종합점수", ascending=False)
Out[85]:
| 분류 | 장소부족 | 비용부족 | 종합점수 | |
|---|---|---|---|---|
| 4 | 중랑구 | 0.682927 | 1.000000 | 0.809756 |
| 1 | 동작구 | 0.878049 | 0.633333 | 0.780163 |
| 2 | 중구 | 0.792683 | 0.633333 | 0.728943 |
| 3 | 은평구 | 0.743902 | 0.500000 | 0.646341 |
| 8 | 성동구 | 0.548780 | 0.755556 | 0.631491 |
| 5 | 도봉구 | 0.609756 | 0.633333 | 0.619187 |
| 0 | 종로구 | 1.000000 | 0.022222 | 0.608889 |
| 11 | 강동구 | 0.439024 | 0.722222 | 0.552304 |
| 9 | 관악구 | 0.524390 | 0.466667 | 0.501301 |
| 6 | 양천구 | 0.573171 | 0.244444 | 0.441680 |
| 7 | 구로구 | 0.560976 | 0.111111 | 0.381030 |
| 14 | 영등포구 | 0.317073 | 0.388889 | 0.345799 |
| 12 | 마포구 | 0.426829 | 0.144444 | 0.313875 |
| 10 | 용산구 | 0.451220 | 0.088889 | 0.306287 |
| 16 | 광진구 | 0.219512 | 0.433333 | 0.305041 |
| 18 | 동대문구 | 0.182927 | 0.477778 | 0.300867 |
| 13 | 서초구 | 0.353659 | 0.155556 | 0.274417 |
| 21 | 송파구 | 0.134146 | 0.322222 | 0.209377 |
| 22 | 강남구 | 0.097561 | 0.366667 | 0.205203 |
| 15 | 강북구 | 0.268293 | 0.000000 | 0.160976 |
| 23 | 강서구 | 0.085366 | 0.266667 | 0.157886 |
| 24 | 서대문구 | 0.000000 | 0.377778 | 0.151111 |
| 17 | 노원구 | 0.182927 | 0.000000 | 0.109756 |
| 19 | 성북구 | 0.170732 | 0.011111 | 0.106883 |
| 20 | 금천구 | 0.134146 | 0.044444 | 0.098266 |
In [88]:
# 종합 점수를 기준으로 상위 5항목만 df_top5 에 저잠
df_top5 = df_sort.sort_values(by="종합점수", ascending=False).head()
df_top5
Out[88]:
| 분류 | 장소부족 | 비용부족 | 종합점수 | |
|---|---|---|---|---|
| 4 | 중랑구 | 0.682927 | 1.000000 | 0.809756 |
| 1 | 동작구 | 0.878049 | 0.633333 | 0.780163 |
| 2 | 중구 | 0.792683 | 0.633333 | 0.728943 |
| 3 | 은평구 | 0.743902 | 0.500000 | 0.646341 |
| 8 | 성동구 | 0.548780 | 0.755556 | 0.631491 |
In [92]:
# 분류를 그룹을 기준으로 시각화
g = sns.barplot(x="분류", y="종합점수", data=df_top5, hue="분류")

In [96]:
# dataset 다시 들고와서 저장
# 성별을 가져와서 파악해볼 것임
df = pd.read_csv("../data_set/3.시각화/report.txt", sep="\t")
df
Out[96]:
| 기간 | 대분류 | 분류 | 운동을 할 충분한 시간이 없어서 | 함께 운동을 할 사람이 없어서 | 운동을 할 만한 장소가 없어서 | 운동을 싫어해서 | 운동을 할 충분한 비용이 없어서 | 기타 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019 | 서울시 | 서울시 | 46.8 | 5.0 | 4.3 | 37.3 | 5.2 | 1.4 |
| 1 | 2019 | 성별 | 남자 | 52.4 | 4.4 | 4.9 | 32.4 | 4.9 | 1.1 |
| 2 | 2019 | 성별 | 여자 | 42.5 | 5.6 | 3.9 | 41.0 | 5.4 | 1.7 |
| 3 | 2019 | 연령별 | 10대 | 55.3 | 4.8 | 3.9 | 32.6 | 3.5 | - |
| 4 | 2019 | 연령별 | 20대 | 46.0 | 4.2 | 4.5 | 38.8 | 6.4 | 0.1 |
| 5 | 2019 | 연령별 | 30대 | 59.9 | 5.2 | 2.9 | 27.3 | 4.5 | 0.2 |
| 6 | 2019 | 연령별 | 40대 | 54.1 | 3.9 | 2.9 | 35.5 | 3.3 | 0.4 |
| 7 | 2019 | 연령별 | 50대 | 46.1 | 6.2 | 4.5 | 36.8 | 5.6 | 0.8 |
| 8 | 2019 | 연령별 | 60대 이상 | 26.6 | 6.0 | 6.6 | 48.7 | 6.6 | 5.6 |
| 9 | 2019 | 학력별 | 중졸 이하 | 24.7 | 6.2 | 4.8 | 48.6 | 7.3 | 8.5 |
| 10 | 2019 | 학력별 | 고졸 이하 | 44.3 | 5.3 | 5.6 | 38.6 | 5.5 | 0.7 |
| 11 | 2019 | 학력별 | 대졸 이하 | 53.1 | 4.7 | 3.3 | 34.0 | 4.6 | 0.3 |
| 12 | 2019 | 학력별 | 대학원 이상 | 61.2 | 3.0 | 5.6 | 29.0 | 0.9 | 0.3 |
| 13 | 2019 | 소득별 | 100만원 미만 | 10.7 | 8.4 | 9.9 | 50.7 | 9.4 | 10.9 |
| 14 | 2019 | 소득별 | 100-200만원 미만 | 29.6 | 5.6 | 6.0 | 49.1 | 7.4 | 2.3 |
| 15 | 2019 | 소득별 | 200-300만원 미만 | 42.8 | 7.3 | 3.9 | 39.5 | 5.1 | 1.4 |
| 16 | 2019 | 소득별 | 300-400만원 미만 | 50.6 | 4.3 | 4.2 | 35.5 | 4.8 | 0.7 |
| 17 | 2019 | 소득별 | 400-500만원 미만 | 48.0 | 4.6 | 3.3 | 38.7 | 5.3 | 0.2 |
| 18 | 2019 | 소득별 | 500만원 이상 | 52.8 | 4.3 | 4.0 | 33.4 | 4.5 | 1 |
| 19 | 2019 | 혼인상태별 | 기혼 | 48.7 | 4.5 | 4.1 | 37.3 | 4.6 | 0.7 |
| 20 | 2019 | 혼인상태별 | 미혼 | 50.2 | 4.9 | 4.0 | 35.1 | 5.6 | 0.2 |
| 21 | 2019 | 혼인상태별 | 이혼/사별/기타 | 31.5 | 7.2 | 5.7 | 42.4 | 6.4 | 6.9 |
| 22 | 2019 | 지역대분류 | 도심권 | 53.8 | 3.8 | 7.2 | 28.3 | 4.0 | 2.9 |
| 23 | 2019 | 지역대분류 | 동북권 | 44.5 | 3.5 | 4.1 | 40.6 | 5.5 | 1.8 |
| 24 | 2019 | 지역대분류 | 서북권 | 50.7 | 6.6 | 5.1 | 31.4 | 5.3 | 0.9 |
| 25 | 2019 | 지역대분류 | 서남권 | 47.1 | 6.7 | 4.7 | 35.9 | 4.8 | 0.8 |
| 26 | 2019 | 지역대분류 | 동남권 | 46.3 | 4.7 | 3.1 | 38.9 | 5.4 | 1.5 |
| 27 | 2019 | 종로구 | 종로구 | 62.2 | 0.4 | 9.4 | 25.9 | 2.1 | - |
| 28 | 2019 | 중구 | 중구 | 50.3 | 3.0 | 7.7 | 25.7 | 7.6 | 5.7 |
| 29 | 2019 | 용산구 | 용산구 | 48.9 | 7.5 | 4.9 | 32.6 | 2.7 | 3.4 |
| 30 | 2019 | 성동구 | 성동구 | 46.5 | 4.3 | 5.7 | 34.2 | 8.7 | 0.6 |
| 31 | 2019 | 광진구 | 광진구 | 42.0 | 5.7 | 3.0 | 43.5 | 5.8 | - |
| 32 | 2019 | 동대문구 | 동대문구 | 44.5 | 4.5 | 2.7 | 41.9 | 6.2 | 0.1 |
| 33 | 2019 | 중랑구 | 중랑구 | 46.7 | 2.2 | 6.8 | 32.8 | 10.9 | 0.5 |
| 34 | 2019 | 성북구 | 성북구 | 33.3 | 3.4 | 2.6 | 58.0 | 2.0 | 0.7 |
| 35 | 2019 | 강북구 | 강북구 | 21.3 | 5.3 | 3.4 | 68.1 | 1.9 | - |
| 36 | 2019 | 도봉구 | 도봉구 | 52.0 | 3.2 | 6.2 | 30.8 | 7.6 | 0.3 |
| 37 | 2019 | 노원구 | 노원구 | 56.3 | 1.6 | 2.7 | 30.1 | 1.9 | 7.4 |
| 38 | 2019 | 은평구 | 은평구 | 42.7 | 8.8 | 7.3 | 34.3 | 6.4 | 0.5 |
| 39 | 2019 | 서대문구 | 서대문구 | 69.8 | 0.8 | 1.2 | 21.9 | 5.3 | 1 |
| 40 | 2019 | 마포구 | 마포구 | 46.6 | 8.1 | 4.7 | 35.8 | 3.2 | 1.5 |
| 41 | 2019 | 양천구 | 양천구 | 66.2 | 5.7 | 5.9 | 17.9 | 4.1 | 0.1 |
| 42 | 2019 | 강서구 | 강서구 | 38.5 | 3.8 | 1.9 | 50.5 | 4.3 | 1 |
| 43 | 2019 | 구로구 | 구로구 | 45.3 | 5.7 | 5.8 | 39.0 | 2.9 | 1.3 |
| 44 | 2019 | 금천구 | 금천구 | 53.6 | 2.4 | 2.3 | 37.6 | 2.3 | 1.7 |
| 45 | 2019 | 영등포구 | 영등포구 | 50.2 | 6.7 | 3.8 | 33.9 | 5.4 | - |
| 46 | 2019 | 동작구 | 동작구 | 39.1 | 13.9 | 8.4 | 31.1 | 7.6 | - |
| 47 | 2019 | 관악구 | 관악구 | 44.4 | 8.8 | 5.5 | 34.2 | 6.1 | 1 |
| 48 | 2019 | 서초구 | 서초구 | 49.9 | 4.3 | 4.1 | 36.6 | 3.3 | 1.8 |
| 49 | 2019 | 강남구 | 강남구 | 40.7 | 4.2 | 2.0 | 46.4 | 5.2 | 1.6 |
| 50 | 2019 | 송파구 | 송파구 | 47.6 | 5.0 | 2.3 | 39.4 | 4.8 | 1 |
| 51 | 2019 | 강동구 | 강동구 | 47.0 | 5.2 | 4.8 | 32.4 | 8.4 | 2.3 |
In [99]:
# 대분류의 성별 의 행만 가져옴
df_gender = df[df['대분류'].isin(["성별"])]
df_gender
Out[99]:
| 기간 | 대분류 | 분류 | 운동을 할 충분한 시간이 없어서 | 함께 운동을 할 사람이 없어서 | 운동을 할 만한 장소가 없어서 | 운동을 싫어해서 | 운동을 할 충분한 비용이 없어서 | 기타 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2019 | 성별 | 남자 | 52.4 | 4.4 | 4.9 | 32.4 | 4.9 | 1.1 |
| 2 | 2019 | 성별 | 여자 | 42.5 | 5.6 | 3.9 | 41.0 | 5.4 | 1.7 |
In [100]:
features = [
'운동을 할 충분한 시간이 없어서',
'함께 운동을 할 사람이 없어서'
]
In [102]:
pg = sns.PairGrid( df_gender, y_vars="분류", x_vars=features, height=5, hue="분류")
pg.map(sns.barplot)
Out[102]:
<seaborn.axisgrid.PairGrid at 0x20b60ef5990>

In [103]:
df_age = df[df["대분류"].isin(["연령별"]) ]
df_age
Out[103]:
| 기간 | 대분류 | 분류 | 운동을 할 충분한 시간이 없어서 | 함께 운동을 할 사람이 없어서 | 운동을 할 만한 장소가 없어서 | 운동을 싫어해서 | 운동을 할 충분한 비용이 없어서 | 기타 | |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 2019 | 연령별 | 10대 | 55.3 | 4.8 | 3.9 | 32.6 | 3.5 | - |
| 4 | 2019 | 연령별 | 20대 | 46.0 | 4.2 | 4.5 | 38.8 | 6.4 | 0.1 |
| 5 | 2019 | 연령별 | 30대 | 59.9 | 5.2 | 2.9 | 27.3 | 4.5 | 0.2 |
| 6 | 2019 | 연령별 | 40대 | 54.1 | 3.9 | 2.9 | 35.5 | 3.3 | 0.4 |
| 7 | 2019 | 연령별 | 50대 | 46.1 | 6.2 | 4.5 | 36.8 | 5.6 | 0.8 |
| 8 | 2019 | 연령별 | 60대 이상 | 26.6 | 6.0 | 6.6 | 48.7 | 6.6 | 5.6 |
In [104]:
pg = sns.PairGrid( df_age, y_vars="분류", x_vars=features, height=5, hue="분류")
pg.map(sns.barplot)
Out[104]:
<seaborn.axisgrid.PairGrid at 0x20b611fb2d0>

In [107]:
df_age["운동할 수 있음"] = df_age["운동을 할 충분한 시간이 없어서"].apply(lambda x: 100 - x)
df_age["함께 운동할 수 있음"] = df_age["함께 운동을 할 사람이 없어서"]
f = ["운동할 수 있음", "함께 운동할 수 있음"]
pg = sns.PairGrid( df_age, y_vars="분류", x_vars=features, height=5, hue="분류")
pg.map(sns.barplot)
Out[107]:
<seaborn.axisgrid.PairGrid at 0x20b5cb14790>
In [110]:
df_age["종합점수"] = df_age["운동할 수 있음"] + df_age["함께 운동할 수 있음"]
f = ["운동할 수 있음", "함께 운동할 수 있음", "종합점수"]
pg = sns.PairGrid( df_age, y_vars="분류", x_vars=f, height=5, hue="분류")
pg.map(sns.barplot)
df_age[["분류", "종합점수"]]
Out[110]:
| 분류 | 종합점수 | |
|---|---|---|
| 3 | 10대 | 49.5 |
| 4 | 20대 | 58.2 |
| 5 | 30대 | 45.3 |
| 6 | 40대 | 49.8 |
| 7 | 50대 | 60.1 |
| 8 | 60대 이상 | 79.4 |

728x90
'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 과적합 및 하이퍼파라미터 (0) | 2024.05.27 |
|---|---|
| [머신러닝] 지도학습 ( 분류, 회귀 ), 평가지표 선택하는 방법 (0) | 2024.05.24 |
| [머신러닝] 시각화 ( mataplotlib, seaborn ) (0) | 2024.05.24 |
| [머신러닝] 실습 예제 및 풀이 (1) | 2024.05.23 |
| [머신러닝] 데이터 전처리 ( 그룹 ) (0) | 2024.05.23 |