환경 세팅
jupyter notebook 설치 - 아나콘다에서 제공하는 하나의 툴
※ 파이썬 설치가 되어있어야 함 ※
기존에 설치되어 있던 anaconda3 를 삭제하고 진행


Distribution | Anaconda
Anaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com


data_set 다운로드
출처 : https://github.com/ChoHeeWon00/data_set
GitHub - ChoHeeWon00/data_set
Contribute to ChoHeeWon00/data_set development by creating an account on GitHub.
github.com
파이썬 기본 문법
arr = [10, 20, "안녕"];
print(arr);
print(type(arr));
for i in arr :
print(i);
print("=" * 20);
dic = {};
dic['num'] = "아무거나";
print(dic);
for k, v in dic.items():
print(k, " : ", v);
arr = 100;
print(type(arr));
while arr < 103:
arr += 1;
print( arr );
for i in range(5):
print(i);
for i in range(1,5):
print(i);
bool = True
if bool == True:
print("같다");
bool = 100;
if bool > 90:
print("90보다 크다")
elif bool > 80:
print("80보다 크다")
else:
print("그 외의 값")
def test(a, b, c):
print("test 호출");
arr = [10, 20, 30];
arr.append(a);
arr.append(b);
arr.append(c);
return arr;
list_num = test(10, 1.123, "안녕");
print(list_num);
Anaconda3 설치


- Dataset 구하는 사이트 -
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com



Jupyter 기본 경로 : C 드라이브 > 사용자 > 사용중인 home 디렉토리
기본 경로를 변경할 것임











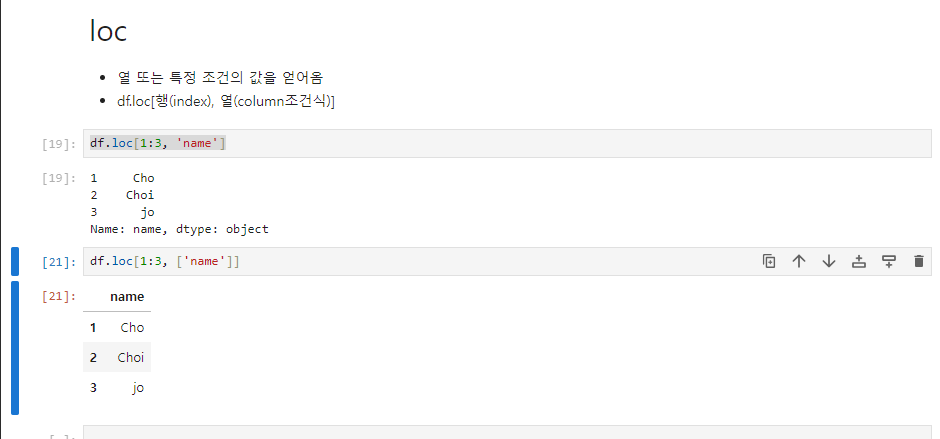

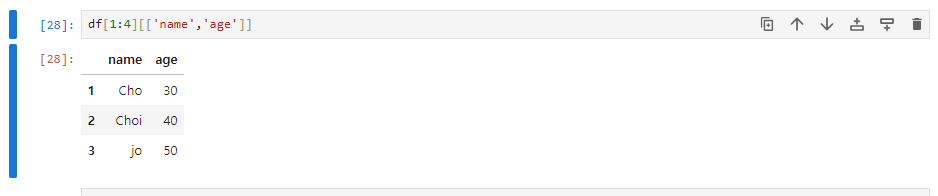











내용 정리 파일
실습 예제
비밀번호는 댓글
예제 풀이
머신러닝 예시
데이터의 전처리 과정이 필요하나, 현재 생략된 상태
( 전처리 과정을 진행하기 위해 위의 기본 코드들을 학습해야 한다 )
Survived : 생존 여부
Pclass : 티켓 클래스 ( 1등석, 2등석, 3등석 )
Sex : 성별
Age : 나이
SibSp : 동반한 형재자매와 배우자의 수
Parch : 동반한 부모, 자식의 수
Fare : 티켓의 요금



'BE > 머신러닝(ML)' 카테고리의 다른 글
| [머신러닝] 데이터 전처리 ( 시계열 ) (1) | 2024.05.23 |
|---|---|
| [머신러닝] 데이터 전처리 ( 원 핫 인코딩 ) (0) | 2024.05.23 |
| [머신러닝] 모델 생성 및 평가 (0) | 2024.05.23 |
| [머신러닝] 데이터 전처리 ( 이상치, 중복 데이터, 문자 데이터 ) (0) | 2024.05.23 |
| [머신러닝] 데이터 전처리( 결측값 대체, 치환, 삭제 ) (1) | 2024.05.22 |