- TIL -
구현 목표)
SSL 인증서를 발급하여 www.random-chat.site 경로와 api.random-chat.site 경로를 각각 443 포트를 사용해 https 요청을 받도록 적용할 것이다.
이때 지금 구현한 http 경로로 접근하는 요청은 전부 443 포트로 매핑하여 경로를 우회하여 접근되게끔 설정할 것이다.
SSL 인증서 발급을 위해 Cerbot 설치 및 인증서 발급)
1) apt update 진행
$ sudo apt-get update
$ sudo apt-get upgrade
2) SSL 발급을 위해 cerbot 을 설치
$ sudo apt-get install python3-certbot-nginxCerbot 은 Let's Encrypt 인증서를 사용하여 HTTPS 를 사용할 수 있게 해주는 오픈소스 툴이다.
3) nginx 컨테이너 동작 중지
$ sudo docker stop $(sudo docker ps -q)포트 충돌이 날 수 있기 때문에 잠시 올려뒀던 모든 컨테이너를 중지
4) 컨테이너를 중지시킨 후에도 자꾸 80포트를 점유중이라는 문구가 나와 80포트에 대한 모든 프로세스를 종료 후 5번 실행
$ sudo fuser -k 80/tcp5) 를 먼저 시도 후 정상적으로 SSL 인증서가 발급되었다면 4) 는 실행할 필요가 없다.
5) 설치한 cerbot 툴을 사용해서 SSL 인증서를 발급
$ sudo certbot certonly --standalone -d www.random-chat.site -d api.random-chat.sitecertonly 옵션을 적용하지 않으면 SSL 인증서를 발급하면서 nginx 설정까지 자동으로 해버리는데 현재 Docker 이미지를 사용해서 구현하는
입장에서 nginx.conf 설정과 docker-compose.yml 설정을 수동으로 진행해야 하는 부분이 있어서 설정은 수동으로 진행하도록 설치하였다.
-d 옵션을 사용해서 인증서를 발급받을 도메인 정보를 각각 기입해줬다.
--standalone 을 사용해서 Cerbot 이 자체적으로 간단한 웹 사이트를 작동시켜 해당 도메인의 소유권을 확인한 뒤 인증서를 발급한다.
인증서 발급 중 이메일을 기재하고 약관에 동의한다고 y 키를 눌러 승인해주면 된다
6) 인증서가 정상적으로 발급되었는지 확인

/etc/letsencrypt/live/www.random-chat.site 경로에 www.random-chat.site 도메인의 인증서와 api.random-chat.site 도메인의
인증서가 합쳐진 인증서 파일이 생성되었다.
7) 인증서가 정상적으로 두 도메인 모두 발급되었는지 확인
$ sudo openssl x509 -in /etc/letsencrypt/live/www.random-chat.site/fullchain.pem -text | grep DNS발급된 fullchain.pem 인증서의 텍스트 중 DNS 문자열을 가지고 있는 내용을 출력

8) Docker Compose 재실행
$ sudo docker-compose up -d --buildDocker Compose 를 재실행, 이제부턴 발급된 인증서를 설정하기만 하면 되기 때문에 Docker Compose 를 다시 올려준다.
Nginx 설정)
1) 설치된 인증서 디렉토리를 nginx 설정 디렉토리쪽으로 이동

2) Dockerfile 설정
$ sudo vi Dockerfilevi 편집기로 Dockerfile 을 열어서 수정
From nginx:latest
COPY nginx.conf /etc/nginx/nginx.conf
COPY ./letsencrypt /etc/letsencryptletsencrypt 디렉토리를 도커 컨테이너 내의 /etc/ 디렉토리로 카피하여 사용
3) nginx.conf 설정파일 수정
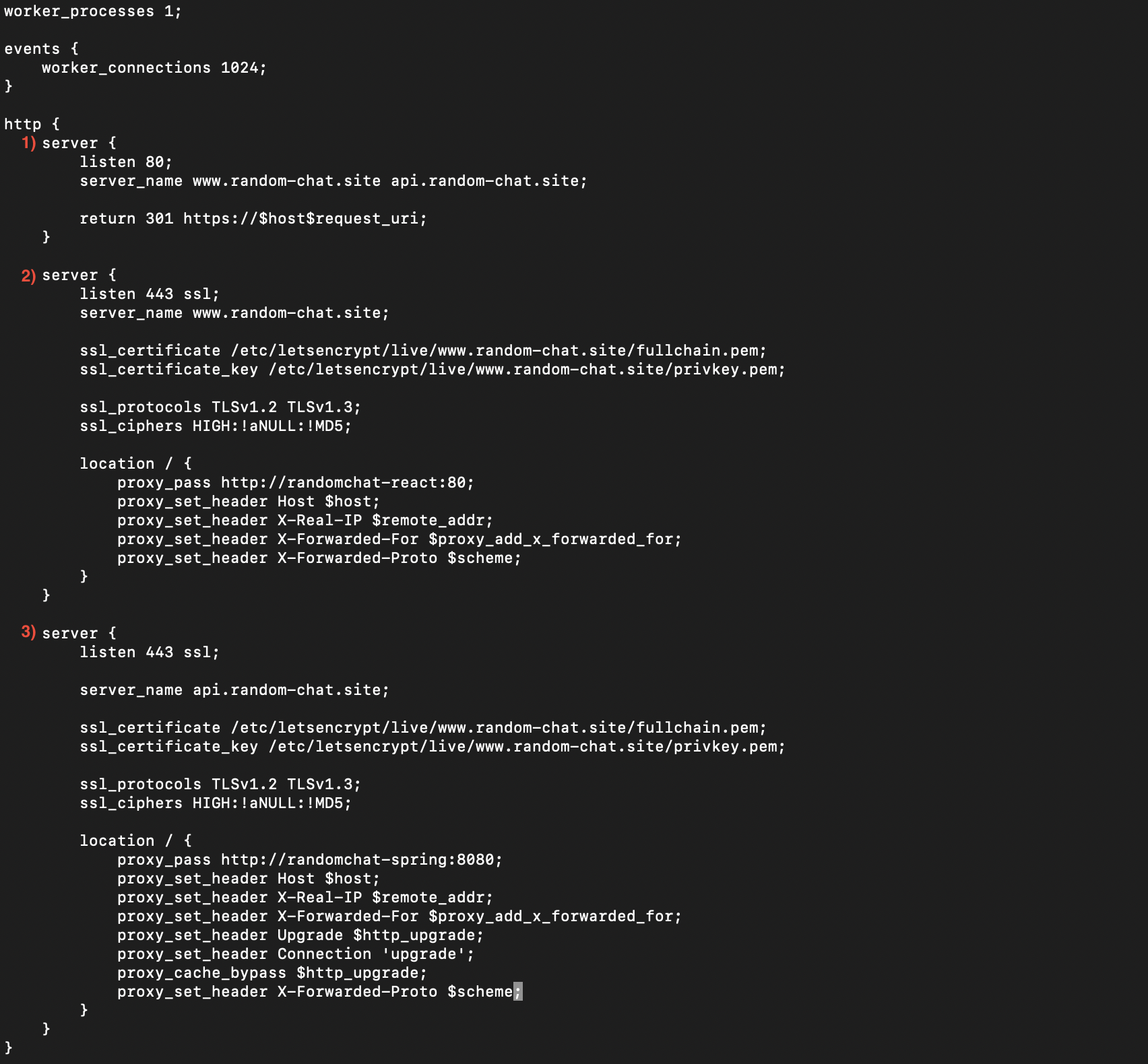
1) 80 포트인 http 를 통해 접속되는 도메인을 https 경로로 우회
2) 443 포트(https)로 접속되는 www.random-chat.site 요청을 ssl 로 처리
3) 443 포트(https)로 접속되는 api.random-chat.site 요청을 ssl 로 처리
ssl_certificate, ssl_certificate_key 는 인증서와 인증서 키가 있는 위치를 설정
ssl_protocols, ssl_ciphers 는 지원할 SSL/TLS 프로토콜을 명시, 암호와 알고리즘 우선순위 설정
proxy_set_header X-Forwarded-Proto $scheme 은 클라이언트의 원래 요청이 HTTPS로 들어왔는지, HTTP로 들어왔는지 백엔드 서버가 알 수 있도록 하기 위해 사용
docker-compose.yml 설정)
version: "3.8"
services:
mysql:
image: mysql:8.0
container_name: randomchat-mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: "yy29623358"
MYSQL_DATABASE: "randomchat"
MYSQL_USER: "youngho3358"
MYSQL_PASSWORD: "yy29623358"
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql
spring:
build:
context: ./spring
container_name: randomchat-spring
restart: always
environment:
SPRING_DATASOURCE_URL: jdbc:mysql://randomchat-mysql:3306/randomchat
SPRING_DATASOURCE_USERNAME: youngho3358
SPRING_DATASOURCE_PASSWORD: yy29623358
ports:
- "8080:8080"
depends_on:
- mysql
react:
build:
context: ./react
container_name: randomchat-react
restart: always
volumes:
- ./react/build:/usr/share/nginx/html
ports:
- "3000:80"
nginx:
build:
context: ./nginx
container_name: randomchat-nginx
restart: always
ports:
- "80:80"
- "443:443"
depends_on:
- spring
- react
volumes:
- ./nginx/letsencrypt:/etc/letsencrypt
volumes:
mysql_data:nginx 설정 부분에 443 포트를 매핑, volumes 로 로컬의 randomchat/nginx/letsencrypt 경로를 도커 컨테이너 내의 /etc/letsencrypt 로 연동
즉, 로컬의 randomchat/nginx/letsencrypt 의 파일 정보가 변경되면 도커 컨테이너의 /etc/letsencrypt 가 자동으로 변경된다는 의미이다.
위 설정을 한 이유는 letsencrypt 의 경우 90일의 무료 인증서 기간을 제공하는데 추후 crontab 기능으로 90일 마다 인증서를 갱신하게끔
설정하여 도커 컨테이너의 인증서 파일을 90일 기준으로 갱신처리하기 위함이다.
도커 컴포즈 재빌드)
1) 전체 빌드 후 재시작
$ sudo docker-compose up --build
2) 전체 빌드 후 백그라운드에서 실행 (-d 옵션)
$ sudo docker-compose up --build -d
3) 기존 컨테이너 정리 후 빌드
$ sudo docker-compose down && docker-compose up --build
4) 캐시를 무시하고 빌드
$ sudo docker-compose build --no-cache && sudo docker-compose up -d( 빌드 후에도 변경사항이 적용되지 않는 경우 실행 - 이전 캐시 정보로 계속 빌드하는 경우 )
위 빌드 방법 중 나는 캐시정보 때문인지 네트워크 정보 때문인지 빌드가 되지 않아 싹 날려버리고 아래와 같이 진행했다.
$ sudo docker-compose down --volumes --remove-orphans
$ sudo docker network prune -f
$ sudo docker volume prune -f
$ sudo docker-compose up --build -d모든 컨테이너 볼륨, 네트워크, 캐시를 제거한 뒤 재빌드
문제 발생 및 해결)
인증서 권한문제 해결)
도커 컨테이너를 재실행 했을때 nginx 컨테이너가 계속 restarting 으로 표시되는 것을 확인....
2024/12/22 13:27:55 [emerg] 1#1: cannot load certificate "/etc/letsencrypt/live/www.random-chat.site/fullchain.pem": BIO_new_file() failed (SSL: error:80000002:system library::No such file or directory:calling fopen(/etc/letsencrypt/live/www.random-chat.site/fullchain.pem, r) error:10000080:BIO routines::no such file)
nginx: [emerg] cannot load certificate "/etc/letsencrypt/live/www.random-chat.site/fullchain.pem": BIO_new_file() failed (SSL: error:80000002:system library::No such file or directory:calling fopen(/etc/letsencrypt/live/www.random-chat.site/fullchain.pem, r) error:10000080:BIO routines::no such file)위와 같은 에러 로그가 남는 것을 확인하였다.
파일을 확인하지 못하는 이유는 실제 인증서 파일이 없거나 혹은 권한이 없기 때문이라고 한다.
나는 모든 코드를 sudo 를 사용해 관리자 권한으로 실행했으므로 nginx 에서 COPY 를 통해 파일을 도커 컨테이너로 복사해가도
root 권한이 아닌 이상 읽지 못하는 상태였을 것이다.
1) letsencrypt 디렉토리의 권한 변경
$ sudo chown -R youngho3358:youngho3358 ./letsencrypt
$ sudo chmod -R 755 ./letsencrypt사용자를 root 가 아닌 youngho3358 로 변경 한 뒤 letsencrypt 디렉토리를 모든 사용자에게 읽기, 실행 권한을 부여한 뒤 다시 빌드
권한 문제일거라 생각했지만... 결국 코드를 천천히 살펴보니 docker-compose.yml 파일에 nginx volumes 에
./nginx/letsencrypt:/etc/letsencrypt 로 기재해야 할 부분을 .nginx/letsencrypt:/etc/letsencrypt 로 기재해서 발생했던 문제였다.
겨우 / 하나 빠진걸로 시간을 3시간이나 소비했지만 결과적으로는 권한 문제로도 해당 에러가 발생할 수 있음을 인지하고 해당 디렉토리의
권한을 755 로 유지하기로 하였다.
front api 요청 경로 및 websocket 연결 경로를 https 기준에 맞게 변경)

프론트 요청 주소를 변경하고 다시 빌드하여 사이트를 재배포하였습니다.
Random-Chat
www.random-chat.site
'TIL' 카테고리의 다른 글
| [TIL] 2024.12.25 - Nginx 를 사용해 React 세부 페이지 서빙하기 (2) | 2024.12.25 |
|---|---|
| [TIL] 2024.12.24 - nginx 포트 충돌 오류 해결 (docker, docker compose 충돌) (1) | 2024.12.24 |
| [TIL] 2024.12.21 - 랜덤 1:1 채팅 구현 ( WebSocket, STOMP ) (1) | 2024.12.21 |
| [TIL] 2024.12.14 - 인증 코드 발송 오류 해결 ( 이메일 인증 구현 ) (0) | 2024.12.14 |
| [TIL] 2024.12.13 - 프로젝트 배포하기2 ( Docker Compose 를 사용하여 Spring, React 프로젝트 배포 ) (2) | 2024.12.13 |