trunc, upper, lower
upper(정렬할 컬럼) : 대문자 정렬
lower(정렬할 컬럼) : 소문자 정렬
trunc(출력할 컬럼, 출력할 소수점 자릿 수) : 표현할 값을 표현할 자릿 수 까지만 출력한다
실습 예제
create table test_company(
name varchar2(20),
연봉 varchar2(20),
class varchar2(20)
);
insert into test_company values('hong gil dong_M','3600','Manager');
insert into test_company values('kim gea ddong_M','2555','ManaGer');
insert into test_company values('Go gil dong_M','2800','ManaGER');
insert into test_company values('hong gil dong_E','3111','EmpLoyee');
insert into test_company values('kim gea ddong_E','2600','EmpLoYee');
insert into test_company values('Go gil dong_E','2950','employee');위 코드 선 실행

예제 풀이
select * from test_company;
select * from test_company where upper(class)='MANAGER';
select * from test_company where lower(class)='employee' and 연봉 >= 2800;
select initcap(name), trunc(연봉/12,0) from test_company;
sum , avg , max , min , count , group by , having
create table test_class(class varchar2(10), score number);
Insert into test_class values('A반',11);
insert into test_class values('A반',12);
insert into test_class values('A반',13);
insert into test_class values('B반',21);
insert into test_class values('B반',22);
insert into test_class values('B반',23);
insert into test_class values('1',31);
insert into test_class values('1',32);
insert into test_class values('1',33);
insert into test_class values('',40);위 코드 선 실행
select sum(score) from test_class; -- sum(컬럼) 컬럼의 총 합을 구함
select avg(score) from test_class; -- avg(컬럼) 컬럼의 총 평균을 구함
select max(score), min(score) from test_class; -- max(컬럼), min(컬럼) 컴럼의 최소값 최대 값 출력
select count(class) from test_class; -- 전체 갯수를 구하는데 값이 없는 곳은 갯수로 치지 않는다
select count(*) from test_class; -- 전체 갯수를 출력하는데 값이 없는 곳까지 모두 갯수로 쳐서 출력한다
select class, sum(score) from test_class group by class; -- group by (묶고자하는 컬럼) : 컬럼값이 동일한 것들로 정렬하여 묶어준다
select class, sum(score) from test_class group by class having sum(score)>60;
-- 그룹별로 묶여서 출력된 값 중 score의 합이 60 이상인 것들만 출력!!!
-- group by 를 사용하면 where 절은 사용이 불가능하여 having 절을 사용해야 한다!sum(컬럼) : 컬럼의 총 합을 구함
avg(컬럼) : 컬럼의 총 평균을 구함
max(컬럼) : 컬럼의 최댓값을 출력
min(컬럼) : 컬럼의 최솟값을 출력
count(컬럼) : 컬럼의 데이터 갯수를 출력 ( 데이터가 비어있으면 갯수에 포함되지 않는다 )
count(*) : 전체 갯수를 출력하는데 값이 없는 곳까지 모두 갯수로 쳐서 출력한다
group by (묶고자하는 컬럼) : 컬럼의 데이터가 동일한 것들을 묶어서 출력한다
having (조건문) : group by 를 사용하면 where 문을 사용할 수 없으므로 조건을 추가할때 having 을 사용한다
실습 예제

실습 풀이
select class, count(class) from test_class group by class;
select class, avg(score) from test_class group by class order by avg(score) desc;
select class, min(score), max(score) from test_class group by class;
별칭, inner join
create table test_name(id varchar2(20), class varchar2(20));
Insert into test_name values('홍길동','A반');
insert into test_name values('김개똥','B반');
insert into test_name values('고길동','C반');
create table test_lesson(id varchar2(20), lesson varchar2(20), score number);
insert into test_lesson values('홍길동','python',80);
insert into test_lesson values('홍길동','java',90);
insert into test_lesson values('홍길동','c언어',70);
insert into test_lesson values('김개똥','server2012',70);
insert into test_lesson values('김개똥','linux',90);
insert into test_lesson values('고길동','jsp',100);위 코드 선 실행
select * from test_name;
select * from test_lesson;
select * from test_name, test_lesson; -- id 가 중복되어서 출력됨
select N.*, L.lesson, L.score from test_name N, test_lesson L; -- 별칭을 부여하여 사용
-- N.* : test_name 을 N 으로 별칭하였으므로 N.* 은 test_name 의 모든 칼럼의 값
-- L.lesson : test_lesson 을 L 로 별칭하였으므로 L.lesson 은 test_lesson 의 lesson 칼럼의 값
-- L.score : test_lesson 을 L 로 별칭하였으므로 L.lesson 은 test_lesson 의 score 칼럼의 값
select N.*, L.lesson, L.score from test_name N, test_lesson L
where N.id = L.id; -- L과 N의 ID 값이 같은 값들을 출력
select * from test_name N inner join test_lesson L on N.ID=L.id;
select N.*, L.lesson from test_name N inner join test_lesson L on N.ID=L.id;
DB 툴
( 이 툴 이외에도 무료 툴이 많으니 DB 를 생성할때 툴을 이용하면 된다 )
AQueryTool
AQueryTool은 웹 기반 ERD 툴 + SQL 자동 생성 프로그램입니다.
aquerytool.com
실습 예제
( 클릭 시 확대 )
실습 풀이 1
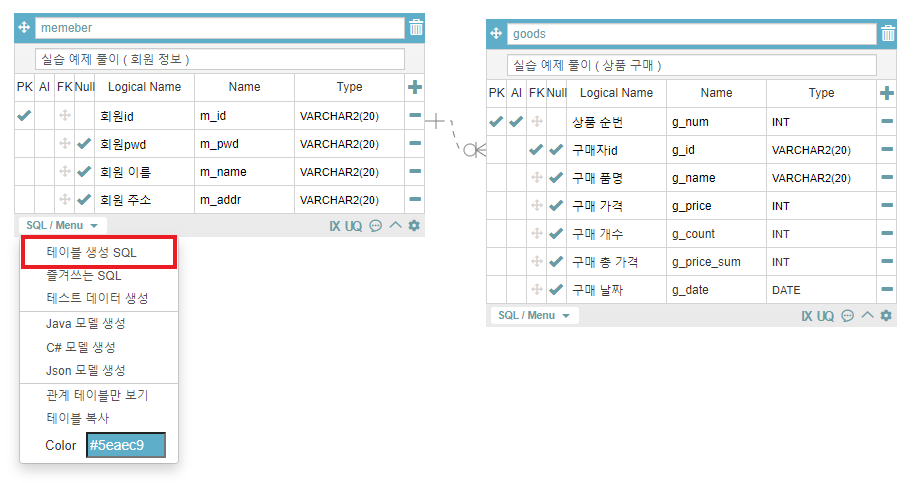
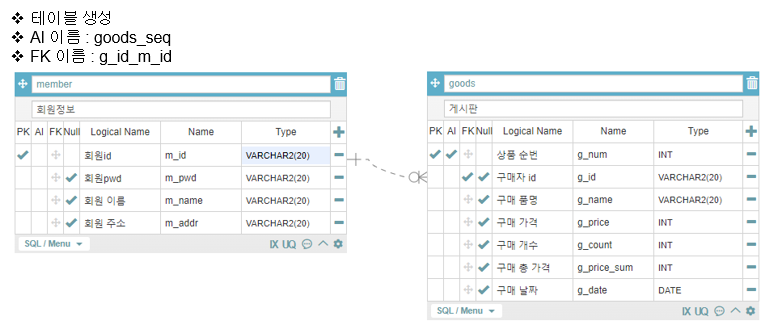
CREATE TABLE memeber
(
m_id VARCHAR2(20) NOT NULL,
m_pwd VARCHAR2(20) NULL,
m_name VARCHAR2(20) NULL,
m_addr VARCHAR2(20) NULL,
PRIMARY KEY (m_id)
);
-- goods 테이블 생성
CREATE TABLE goods
(
g_num INT NOT NULL,
g_id VARCHAR2(20) NULL,
g_name VARCHAR2(20) NULL,
g_price INT NULL,
g_count INT NULL,
g_price_sum INT NULL,
g_date DATE NULL,
PRIMARY KEY (g_num)
);
-- g_num 컬럼에 Auto Increment 설정 ( 자동으로 수가 올라가면서 값이 저장 )
CREATE SEQUENCE goods_SEQ
START WITH 1
INCREMENT BY 1;
-- m_id 와 g_id 를 Foreign Key 로 서로 값을 연동 ( Foreign key 를 적용하면 저 둘의 값은 무조건 동일한 값이 존재해야 한다 )
ALTER TABLE goods
ADD CONSTRAINT FK_goods_g_id_memeber_m_id FOREIGN KEY (g_id)
REFERENCES memeber (m_id) ;tool 에서 가져온 코드로 테이블을 생성
실습 풀이 2
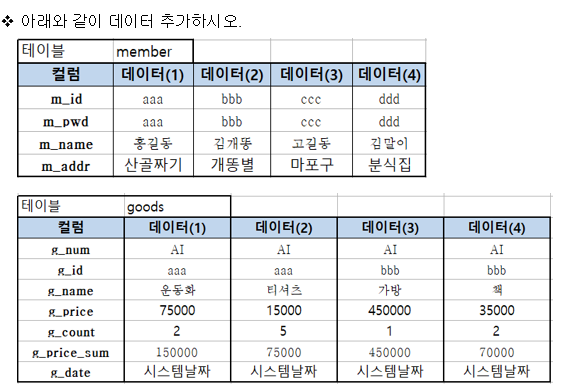
-- 데이터 추가
insert into member(m_id, m_pwd, m_name, m_addr)
values ('aaa', 'aaa', '홍길동', '산골짜기');
insert into member(m_id, m_pwd, m_name, m_addr)
values ('bbb', 'bbb', '김개똥', '개똥별');
insert into member(m_id, m_pwd, m_name, m_addr)
values ('ccc', 'ccc', '고길동', '마포구');
insert into member(m_id, m_pwd, m_name, m_addr)
values ('ddd', 'ddd', '김말이', '분식집');
insert into goods values (1, 'aaa', '운동화', 75000, 2, 150000, sysdate);
insert into goods values (goods_seq.nextval, 'aaa', '티셔츠', 15000, 5, 75000, sysdate);
insert into goods values ((select max(g_num) from goods)+1, 'bbb', '가방', 450000, 1, 450000, sysdate);
insert into goods values ((select max(g_num) from goods)+1, 'bbb', '책', 35000, 2, 70000, sysdate);
select * from member;
select * from goods;
실습 풀이 3
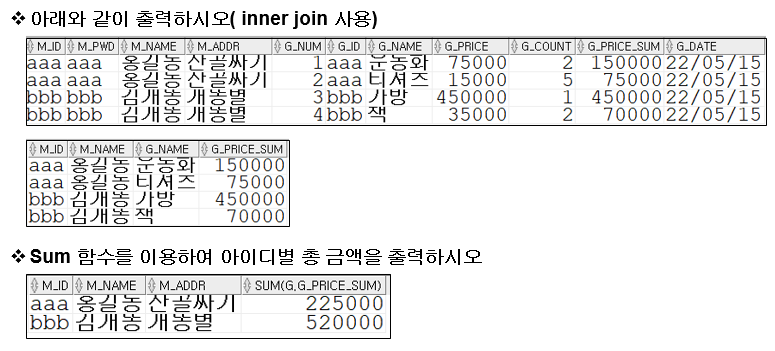
-- inner join 을 사용하여 출력 ( id 가 중복됨을 기준으로 출력 )
select m.*, g.* from member m inner join goods g on m_id=g_id;
-- inner join 을 사용하여 출력 ( m_id, m_name, g_name, g_price_sum 컬럼만 출력 )
select m.m_id, m.m_name, g.g_name, g.g_price_sum from member m inner join goods g on m_id=g_id;
-- sum 함수를 이용하여 아이디 별 총 금액을 출력하시오
select m.m_id, m.m_name, m.m_addr, sum(g.g_price_sum) from member m inner join goods g on m.m_id = g.g_id group by m.m_id, m.m_name, m.m_addr;inner join 사용법, group by 사용법 잘 파악하기!
'국비지원_핀테크' 카테고리의 다른 글
| 19일차_ [java] oracle DB 연동 실습 (0) | 2024.02.29 |
|---|---|
| 18일차_ [java] DB 연동 (1) | 2024.02.28 |
| 17일차_ [DB] Oracle DB 설치, sqldeveloper 설치 및 DB 생성, 기본 문법 (1) | 2024.02.27 |
| 16일차_ [java] Socket 과 Thread 를 활용한 실시간 채팅 프로그램 (0) | 2024.02.26 |
| 15일차_ [java] 미니 프로젝트 ( 파일 입출력, 스트림 클래스 활용 ) (0) | 2024.02.23 |